자바 [JAVA] - 이진 삽입 정렬 (Binary Insertion Sort)
[정렬 알고리즘 모음]
- Binary Insertion Sort [이진 삽입 정렬]
이번 포스팅의 경우 삽입 정렬을 토대로 하기에 반드시 삽입 정렬을 먼저 보고 오시기를 바란다.
만약 필자의 정렬 알고리즘을 시리즈로 보았다면 왜 퀵 정렬 다음에 이진 삽입 정렬을 다루지? 싶을 수도 있다. 일단 왜 그런지부터 말하자면 원래 포스팅 순서대로라면 팀 정렬(Tim Sort)를 다루어야 한다.
그러나 팀 정렬의 경우 Merge Sort(합병 정렬), Insertion Sort(삽입 정렬)이 혼용 된 하이브리드 정렬 알고리즘이다.
여기서 좀 더 구체적 설명해보자면 Insertion Sort의 메커니즘은 같으나, 원소가 들어 갈 위치를 선형 탐색이 아닌 이분 탐색(이진 탐색)을 이용한 방법으로 구현한다.
삽입 정렬의 메커니즘이 무엇이었는지 생각해보자.
정렬 해야 할 target 원소에 대해 target 원소의 인덱스를 기점으로 타겟이 이전 원소보다 크기 전 까지 반복하면서 반복을 멈춘 위치가 target 원소가 들어갈 위치가 되는 것이다.
문제는 선형 탐색이다보니 한 원소에 대해 비교 작업이 최대 N번이 일어난다.
그렇기 때문에 탐색 과정을 이분탐색을 통해 logN 의 탐색 시간 복잡도를 갖도록 하는 방식이 바로 이 번 정렬의 핵심이다.
(전체적인 시간 복잡도 자체는 O(N2)으로 같다. 이 부분은 뒤에서 설명하도록 하겠다.)
- 정렬 방법
먼저 구현을 하기전에 차이점에 대해 잠깐 더 구체적으로 들여다 보자.
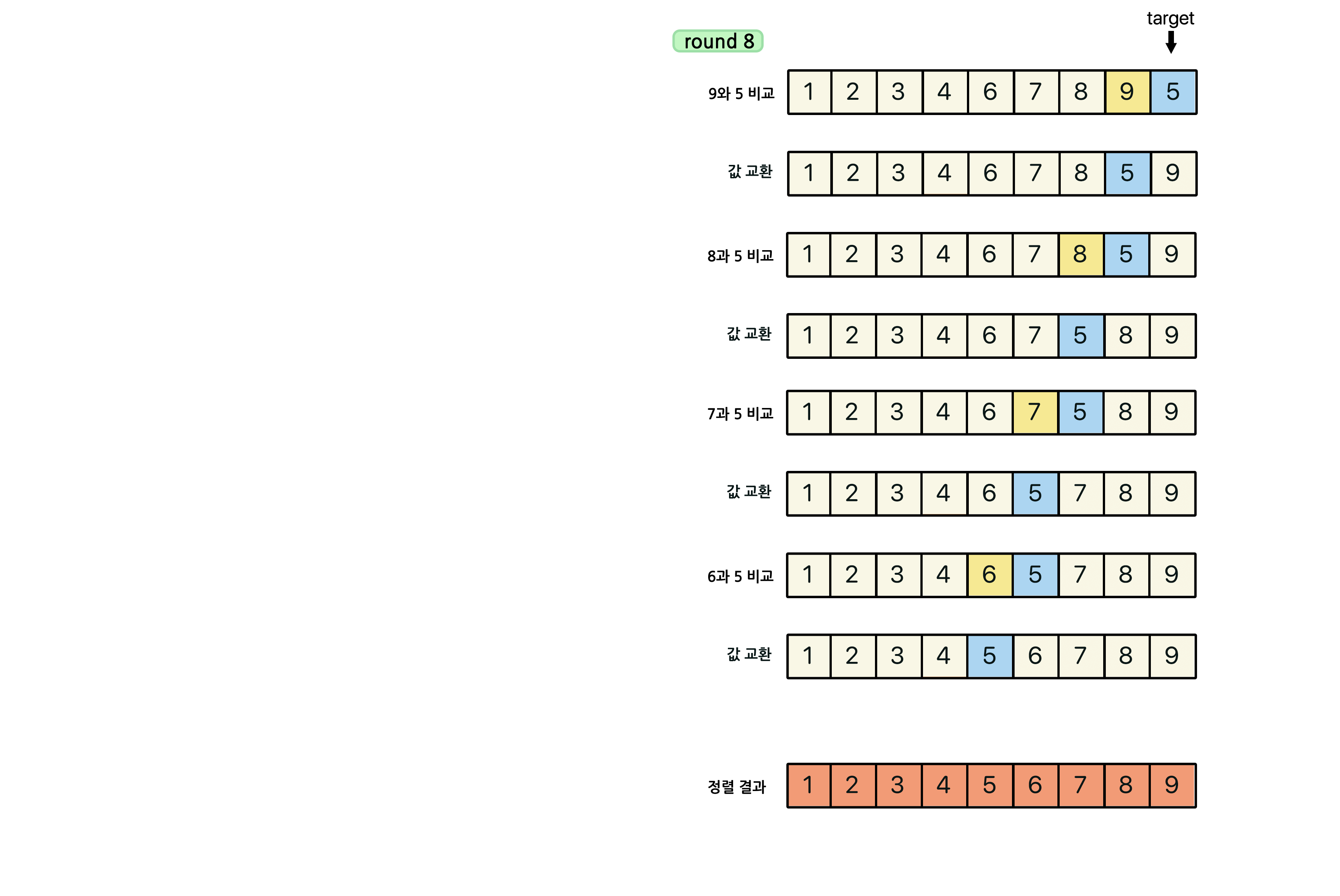
일단 기존의 삽입 정렬 과정은 아래 그림을 참고하면 되고, 코드를 중심으로 보자.

[삽입 정렬 코드]
void insertionSort(int[] a, int size) {
for(int i = 1; i < size; i++) {
// 타겟 넘버
int target = a[i];
int j = i - 1;
// 타겟이 이전 원소보다 크기 전 까지 반복
while(j >= 0 && target < a[j]) {
a[j + 1] = a[j]; // 이전 원소를 한 칸씩 뒤로 미룬다.
j--;
}
a[j + 1] = target;
}
}
위에서 보면 비교 탐색과 동시에 원소를 뒤로 밀어내는 작업을 같이 while문을 통해 이루어지고 있다.
여기서 while 조건문을 보면 j >= 0 과, target < a[j] 이렇게 두 개의 조건이 매 번 반복되고, j >= 0 은 비교 가능한 최대 하한 인덱스인 0까지 탐색이 이루어질 수 있다는 의미이며, target < a[j] 는 배치해야 할 target 원소가 탐색하면서 이전 원소가 target보다 작을 때 까지 반복한다는 것이다.
그러면 이분 탐색을 활용한 정렬은 어떻게 될까? 일단, 이분 탐색을 구현했다고 가정하에 코드를 작성하자면 다음과 같다.
[이진 삽입 정렬 코드]
void insertionSort(int[] a, int size) {
for(int i = 1; i < size; i++) {
// 타겟 넘버
int target = a[i];
// 0 ~ i 사이 이분탐색을 통해 target이 배치 될 위치를 반환
int location = binarySearch(a, 0, i, target);
int j = i - 1;
while(j >= location) {
a[j + 1] = a[j]; // 이전 원소를 한 칸씩 뒤로 미룬다.
j--;
}
a[location] = target;
}
}
별 차이는 없어보인다.
다만, 0 ~ i (현재 target의 위치) 사이 이분탐색을 통해 target 원소가 위치 할 곳을 찾아낸 뒤, target 원소가 해당 위치에 삽입되기 위해 원소들을 한 칸씩 뒤로 밀어주는 것으로 변경되었을 뿐이다.
그럼 일단 구현 메커니즘을 보자.
이진 삽입 정렬의 전체적인 과정은 이렇다. (오름차순을 기준으로 설명)
1. 현재 타겟이 되는 숫자에 대해 이전 위치에 있는 원소들에 들어 갈 위치를 이분 탐색을 통해 얻어낸다. (첫 번째 타겟은 두 번째 원소부터 시작한다.)
2. 들어가야 할 위치를 비우기 위해 후방 원소들을 한칸 씩 밀고 비운 공간에 타겟을 삽입한다.
3. 그 다음 타겟을 찾아 위와 같은 방법으로 반복한다.
즉, 그림으로 보면 다음과 같은 과정을 거친다.


삽입 정렬과 마찬가지로 첫 번째 원소는 타겟이 되어도 비교 할 원소가 없기 때문에 처음 원소부터 타겟이 될 필요가 없고 두 번째 원소부터 타겟이 되면 된다.
그러면 삽입정렬 과정은 알았으니 이를 적용 할 이분 탐색을 구현하는 부분이 관건이겠다.
일단 이분 탐색 과정을 이해해보자면, '정렬 된 상태의 구간' 내에서 중간에 위치한 원소와 비교하여 중간 원소보다 작다면 왼쪽 구간으로, 크다면 오른쪽 구간으로 다시 나누어 탐색하는 과정을 말한다.
쉽게 그림으로 이해하자면 다음과 같다.

위와 같은 메커니즘으로 구현을 하면 된다. 이분 탐색만 따로 떼어서 코드로 구현하자면 다음과 같다.
static int binarySearch(int[] a, int key, int lo, int hi) {
int mid;
while(lo < hi) {
mid = (lo + hi) / 2; // 중간 위치
if(key < a[mid]) { // key < a[mid]라면 탐색 상한선을 중간위치로 변경
hi = mid;
}
else { // 그 외엔 하한선을 중간 다음 위치로 변경
lo = mid + 1;
}
}
return lo;
}
여기서 우리가 주의해야 할 점이 있다. 안정정렬을 하기 위해서는 key < a[mid] 으로 조건을 걸어주어 key값이 중간 위치의 값보다 작을 때만 상한선을 mid로 옮겨주어야 한다.
생각해보자. 우리가 이진탐색하는 범위는 이미 정렬되어있는 상태다. 그리고 우리는 범위에서 key값이 삽입 될 위치를 찾는 것이 관건이다.
이 때 이진 탐색의 범위가 정렬 되어있다는 것은 이미 왼쪽 원소부터 순차적으로 삽입 정렬이 이루어져있다는 의미다.
쉽게 말해 이진 탐색 범위 내에 어떤 원소 a가 key값이랑 동일한 값이더라도 a원소가 key보다 선행원소였기 때문에 안정정렬을 위해서는 key가 a원소 뒤에 위치해야 한다. 즉, key에 대한 중복원소가 존재 할 때, key가 '가장 오른쪽 위치'로 가도록 하기 위함이다.
그렇기 때문에 만약 key <= a[mid] 이렇게 쓰게 된다면 중복 원소일 때 상한선을 왼쪽으로 당겨오기 때문에 '가장 왼쪽 위치'로 배치되어 버리므로, 반드시 key < a[mid] 로 중복 원소가 있을 때 하한선을 오른쪽으로 당겨오게 해주어야 한다.
이에 대한 참고 글은 아래에서도 잘 보여주고 있으니 한 번 확인해보는 것도 좋을 것 같다.
https://en.wikipedia.org/wiki/Binary_search_algorithm#Duplicate_elements
Binary search algorithm - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search This article is about searching a finite sorted array. For searching continuous function values, see bisection method. Search algorithm finding the position of a target value within a
en.wikipedia.org
※그리고 중요한 점이 있다.
여기서는 이해를 돕기 위해 중간 값을 구할 때 mid = (lo + hi) / 2 로 표기하고 있지만, 사실 값의 범위가 클 경우에는 int overflow가 발생할 수 있다.
쉽게 가정해서 lo = 1, hi = 2147483647 (= Integer.MAX_VALUE) 이렇다면,
(lo + hi) 과정에서 overflow가 발생하여 -2147483648 가 되고, 여기에 2를 나누게 되어 -1073741824 라는 잘못된 값을 반환할 수 있다.
이러한 경우 어떻게 해결하냐면, 결국 lo와 hi의 중간 값이라는 것은 lo 로부터 hi까지의 거리를 2로 나눈 값을 더한 값이라는 것이다.
무슨 말인가 하면,
lo = 3, hi = 7 이라 할 때, 중간 값은 (3 + 7) / 2 = 5 일 것이다.
이렇게 위와 같이 표현 할 수 있지만, 사실 생각해보면, 3 ~ 7까지 거리라는 건 결국 3을 기준으로 7이 얼만큼 떨어져 있는가이다.
즉, 3으로부터 4만큼 떨어져있는 지점은 7이라는 것이고, 만약 두 지점의 중간 값이라면, 떨어진 거리의 절반이라는 것이다.
그러면 다음과 같이 표현 할 수 있다.
중간 지점 = 시작점 + (거리 차) / 2
이를 수식으로 표현하면 다음과 같다.
mid = lo + ((hi - lo) / 2)
즉, overflow를 고려했을 때 위와 같이 두 거리의 차에 대한 값을 토대로 중간 값을 구하는게 좋다.
설명은 이해를 돕기 위해 (lo + hi) / 2로 일단 진행을 하고, 코드 작성 부분에서만 lo + ((hi - lo) / 2) 로 작성하도록 하겠다.
이분 탐색을 구현하긴 했는데.. 선형 탐색과는 뭐가 다른거지?
바로 시간복잡도가 O(logN) 이라는 것이다.
N개의 요소를 갖고있는 리스트가 주어졌다고 해보자. 그리고 우리가 이분 탐색에서 N/2 씩 쪼개가면서 탐색을 한다.
즉, 다음과 같다.
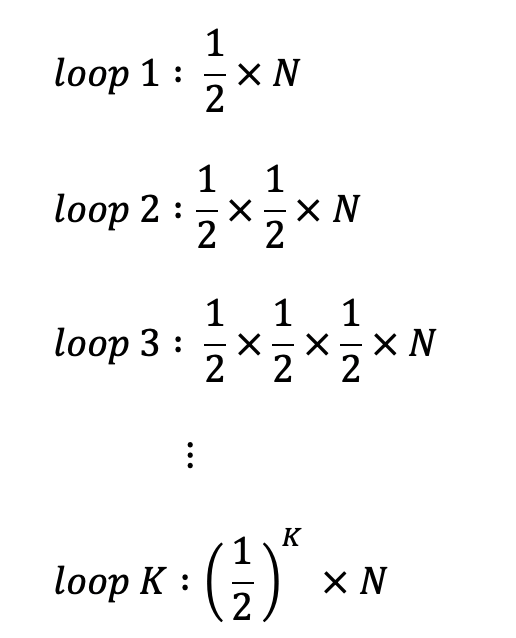
즉, K번 반복한다고 할 때, (1/2)K * N 이 된다는 의미다.
이 때, 위 이미지에서 보면 결국 최악의 경우인 마지막 탐색 범위가 1인 경우가 있을 것이다. K번 반복 했을 때 쪼개진 크기가 1이라고 가정한다면, 결국 K만큼 반복한다고 했으니 K에 대해 풀어보면 다음과 같다.

즉, N개의 리스트에서 어떤 수를 찾는 과정에 대한 시간 복잡도는 O(logN)이라는 것이다.
그럼 의문이 생길 수 있다.
분명 기존의 삽입정렬은 while()문으로 한 번 순회했고, 이진 삽입 정렬은 이분탐색 과정과 원소들을 밀기 위한 순회 과정을 거쳐야 하는데, 오히려 이진 삽입 정렬이 느린 것이 아닌가?
기본적으로 Insertion Sort나, Binary Insertion Sort나 N개의 각 원소들은 삽입시 N개의 원소를 밀어내는 시프트 작업이 발생하기 때문에 O(N2) 의 시간 복잡도를 갖는 것은 같다.
그리고 위에서 말했던 것처럼 while문으로 한 번 순회하는 일반적인 Insertion Sort가 별도의 이진탐색 과정을 거친 뒤 얻은 위치에 원소를 삽입하기 위한 시프트 작업이 발생하는 Binary Insertion Sort보다 빠르게 보이기도 한다.
그러면 왜 이진 삽입 정렬이 필요한 것인가? 이를 이해하기 위해서는 이분 탐색부터 이해해야 한다.
이분 탐색 자체는 앞서 설명했듯, 탐색 비용이 O(logN)의 시간 복잡도를 갖는다. 그리고 우리는 이진 삽입 정렬에서 원소가 들어갈 위치를 찾는 비교작업으로 사용을 하고 있다.
즉, 일반적인 삽입 정렬과의 차이라면 삽입 정렬은 탐색과 시프팅 작업을 동시에 하지만, 이진 삽입 정렬은 탐색을 이분 탐색으로 따로 구한 뒤 시프팅 작업을 거친다.
그럼 이진 삽입 정렬이 빠른 경우는 어떤 경우일까?
바로 '비교 작업 비용'이 '시프팅(스왑) 비용'보다 클 때 이진 삽입 정렬이 좀 더 빠르다는 것이다.
무슨말인가 싶을 수도 있으니 좀 더 구체적으로 설명해보겠다.
// 일반적인 삽입 정렬
int target = a[i];
int j = i - 1;
// 위치와 시프팅을 동시
에 함
while(j >= 0 && target < a[j]) {
a[j + 1] = a[j]; // 시프팅 작업
j--;
}
a[j + 1] = target; // 삽입
위처럼 일반적인 삽입 정렬의 경우 각 반복문 단계마다 j >= 0 과 target < a[j] 조건을 검사를 하면서 순회를 한다.
즉, target 이 들어갈 위치를 찾아가면서(target < a[j]) 동시에 시프팅 작업을 한다.
// 이진 삽입 정렬
int target = a[i];
int location = binarySearch(a, 0, i, target); // 이분 탐색
int j = i - 1;
while(j >= location) {
a[j + 1] = a[j]; // 시프팅 작업
j--;
}
a[location] = target;
반면에 위처럼 이진 삽입 정렬의 경우 비교 작업을 이분탐색을 통해 사용되며, 그 다음 while문에는 j ~ location 까지 시프팅 작업이 이루어진다.
여기서 가장 큰 차이는 바로 '비교작업'의 차이라는 것이다.
앞선 예시에서는 우리가 두 원소를 비교할 때, 모두 int 형으로 '단일 비교'를 전제로 했지만, 사실 해당 타입만 존재하는 건 아니다. 특히 사용자가 만든 클래스 객체에서 비교작업을 하는 경우 대개 단일 비교로 이루어지지 않고 다양한 변수들의 비교를 통해 Comparable 혹은 Comparator을 구현하여 정렬을 할 것이다.
쉽게 말해서 다음과 같다.
// int[] array
// target과 arr[j] 모두 단일 int 값을 갖는다.
while(j >= 0 && target < a[j]) {
// code
}
위 처럼 일반적인 primitive 타입의 배열의 경우 단일 값에 대한 비교를 하기 떄문에 비교 비용이 크지 않지만, 만약 다음과 같은 상황이라면 어떻겠는가?
// Custom[] array
class Main {
// code
// target과 arr[j] 모두 3개의 비교 인자 갖는다.
while(j >= 0 && target.compareTo(a[j])) {
// code
}
}
class Custom implements Comparable<Custom> {
int a, b;
String s;
public Custom(int a, int b, String s) {
this.a = a;
this.b = b;
this.s = s;
}
@Override
public int compareTo(Custom o) {
// a, b, s 순으로 오름차순 정렬
if(this.a == o.a) {
if(this.b == o.b) {
return this.s.compareTo(o.s);
}
return this.b - o.b;
}
return this.a - o.a;
}
}
비교 작업마다 Custom 클래스의 a, b, s 를 모두 비교를 하여 어떤 원소가 더 우선순위가 높은지를 판단해야 한다. 즉, 일반적인 단일 변수에 의한 비교보다 훨씬 비교작업 비용이 크다.
이렇게 여러 변수에 의해 우선순위가 결정되는 객체의 경우에는 결국 삽입정렬처럼 선형 탐색을 하게 된다면 시프팅작업과 탐색 작업이 한 반복문 내에 이루어진다 하더라도 N번의 비교 작업 자체가 비용(Cost)이 비싸진다.
그렇기 때문에 위와 같은 경우에는 별도의 이분탐색을 거치더라도 logN 시간 복잡도를 갖는, 즉 비교 비용을 줄일 수 있는 이분 탐색을 활용하는 것이 더욱 빠르다.
실제로 그럴까? 필자가 테스트 한 것을 보면 이렇다. (테스트는 Java를 통해 실험했고, 얻어온 결과를 파이썬의 plot으로 표현한 것 뿐이다.)
참고로 빨간색이 일반적인 삽입 정렬(Insertion Sort) 이고, 파란색이 이진 삽입 정렬(Binary Insertion Sort)이다.
먼저 무작위로 생성 된 원소들을 갖는 int배열을 각각의 정렬 방식을 통해 얻어진 시간(밀리초) 그래프다.
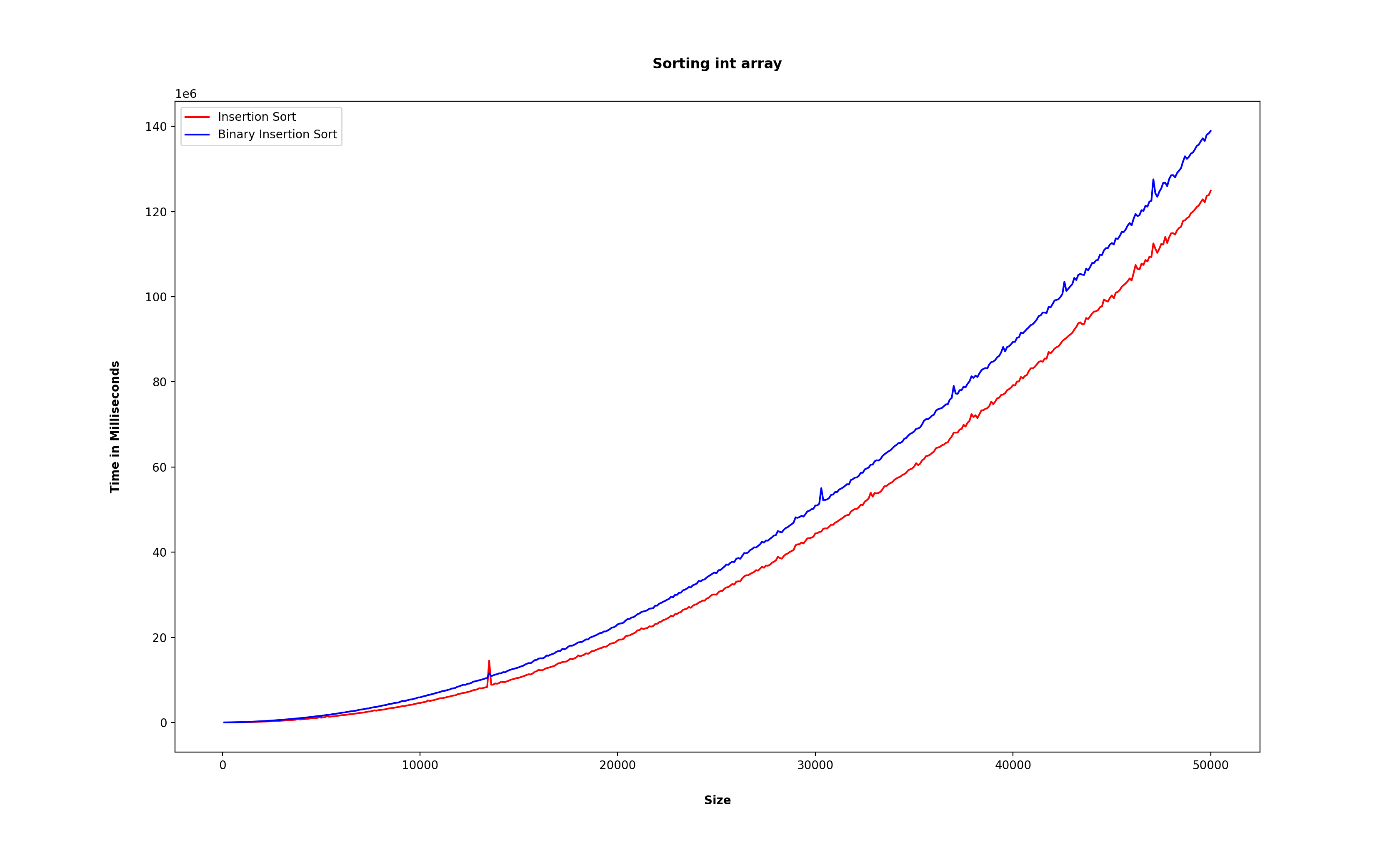
보면 엄청 큰 차이는 아니더라도 분명하게 빨간색 선인 삽입정렬이 좀 더 빠른 걸 볼 수 있다.
그러면 객체를 정렬하는 경우는 어떨까?
위와 동일하게 Custom 클래스를 사용하여 Custom 배열 내의 Custom 원소들의 변수들도 랜덤으로 생성하여 각각 정렬을 했을 때의 어떻게 나타나지는지 보자.
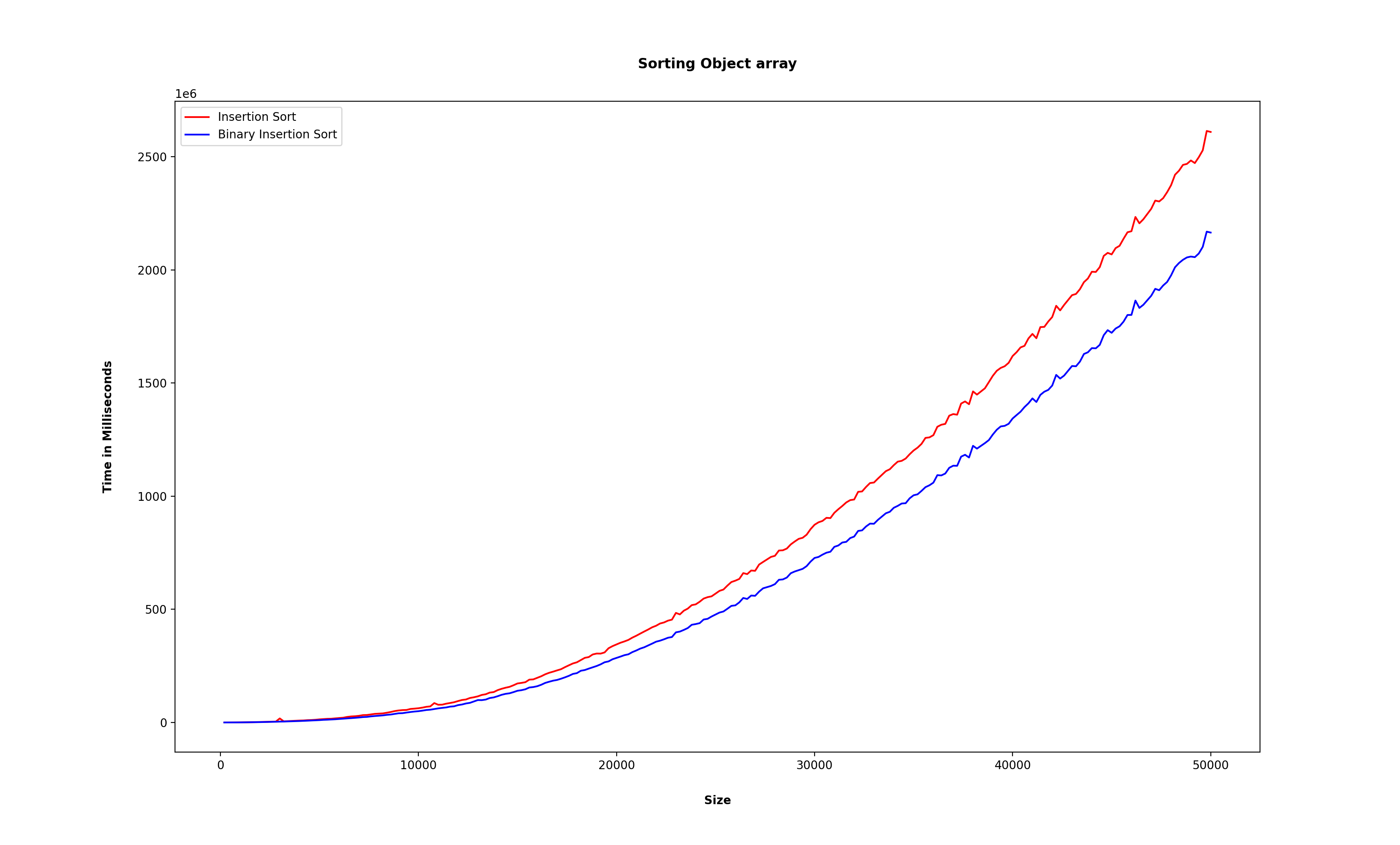
보면 위 그래프와는 달리 이진 삽입 정렬이 더 빠른 것을 볼 수 있다.
위 결과처럼 비교 비용이 비싸질 수록 이진 삽입 정렬은 삽입 정렬에 비해 빠를 것이다.
정리하자면 이진 삽입 정렬이 항상 빠른 것은 아니지만, 비교비용이 스왑비용보다 비싸질 수록 상대적으로 효율이 좋아질 수 있으며 각 원소에서의 이분 탐색은 매우 작은 비용이더라도 작은 logN 비용은 분명 유의미한 차이를 낼 수 있다는 것이다.
그러면 굳이 왜 삽입 정렬을 안쓰고 이진 삽입 정렬을 쓰는가?
자바에서 기본적으로 정렬하는 클래스는 Arrays 클래스의 sort에 의해 이루어진다. (Collections.sort의 경우도 List를 배열로 변환하여 Arrays.sort로 내보낸다.)
그리고 크게 정렬 방식은 두 가지로 나누어지는데 하나는 dual-pivot Quick Sort이고, 다른 하나는 Tim Sort다.
그럼 어느 때 어떤 정렬을 쓰는가를 따져보아야 하는데, 기본적으로 primitive type 일차원 배열의 경우 dual-pivot Quick Sort에 의해 정렬이 된다. (참고로 2차원 배열(ex. int[][])같은 다차원 배열은 Object 타입으로 간다. 쉽게 생각해서 2차원 배열 int[][]의 경우 int[] 타입의 객체가 배열로 된 형태라고 이해하시면 된다.)
Tim Sort는 객체(Object)를 정렬하고자 할 때 쓰인다. 대개 여러 변수에 의해 비교 될 가능성이 높은 타입이 바로 객체이기 때문이지 않을까 싶다. 그리고 실제로 우리가 객체를 정렬하는 경우가 단순히 Wrapper클래스만 있는 것이 아닌 실제 현실 데이터를 반영한 class를 구현하여 이를 리스트로 만들어 다루는 경우가 많다.
그렇기 때문에 오히려 비교 횟수가 많을수록 오버헤드가 커지게 되므로 이럴 때엔 이진 삽입 정렬처럼 비교 횟수를 최소화하는 것이 더욱 효율적일 것이다.
- Binary Insertion Sort 구현하기
사실 삽입 정렬은 이미 다루었고, 이분 탐색에 대한 것은 앞선 설명에서 구현을 했기 때문에 그대로 갖고와주면 된다.
public class BinaryInsertionSort {
public static void binaryInsertionSort(int[] a) {
binaryInsertionSort(a, a.length);
}
private static void binaryInsertionSort(int[] a, int size) {
for(int i = 1; i < size; i++) {
// 타겟 넘버
int target = a[i];
// 이분탐색을 통해 target이 들어가야 할 위치를 얻는다.
int location = binarySearch(a, target, 0, i);
int j = i - 1;
// 시프팅 작업
while(j >= location) {
a[j + 1] = a[j]; // 이전 원소를 한 칸씩 뒤로 미룬다.
j--;
}
a[location] = target;
}
}
// 이분 탐색
private static int binarySearch(int[] a, int key, int lo, int hi) {
int mid;
while(lo < hi) {
// 좀 더 빠르게 하기 위해서 /2 대신 >>> 1을 사용해도 된다.
mid = lo + ((hi - lo) / 2);
if(key < a[mid]) {
hi = mid;
}
else {
lo = mid + 1;
}
}
return hi;
}
}
구현 자체는 어렵지 않다.
결과적으로 타겟 이전 원소가 타겟 숫자보다 크기 직전까지 모든 수를 뒤로 한 칸씩 밀어내는 것이다.
- Binary Insertion Sort 심화 구현하기
이 부분은 이후 팀 정렬 구현에도 활용 될 부분이라 알아두면 좋은 구현 방식이다.
이전까지는 이분 탐색 + 시프팅 작업을 별도로 나누어 작업을 했다. 그러다보니 문제가 하나 발생한다. 바로 최선의 경우에도 반드시 이분 탐색을 거쳐야 하기 때문에 시프팅 작업이 없다고 하더라도 결국 N개의 원소에 대해 이분 탐색 비용인 O(logN)이 발생하기 때문에 Best Case의 경우에 시간 복잡도가 O(NlogN)이 되어버린다.
삽입정렬의 장점이 무엇이었는가? 바로 정렬 된 상태에서 O(N)의 시간 복잡도를 갖는 다는 것이었다.
그렇다면 이진 삽입 정렬도 정렬 된 상태에서의 혹은 부분적으로 정렬 된 상태에서의 시간 복잡도를 줄일 수 있는 방법이 없을까?
방법은 있다. 바로 이분 삽입 정렬을 하기 전에 리스트의 가장 앞부분에 오름차순, 혹은 내림차순이 몇 개까지 연속되어있는지를 확인하고 그 길이를 반환하면 된다.
무슨 말인가 하면, 예로들어 이러한 배열이 있다.
{1, 2, 3, 5, 11, 8, 5, 9}
그러면 이 배열을 정렬하기 전에 index 0부터 오름차순일 때 까지의 길이를 구하는 것이다.
그러면 11을 갖고있는 index 4 까지가 오름차순, 즉 부분적으로 정렬되어있는 구간의 길이인 5를 반환하게 될 것이다. 그리고나서 index 5부터 이진 삽입 정렬을 수행하면 되는 것이다.
반대로 내림차순의 경우도 위와 같이 가능하다. 아래와 같은 배열이 있다고 가정해보자.
{8, 6, 5, 3, 1, 4, 3}
index 0부터 내림차순일 때 까지의 길이를 구한다.
그러면 1을 갖고있는 index 4까지가 내림차순, 즉 부분적으로 정렬되어있는 구간의 길이가 5라는 것이다.
단, 내림차순 일 경우에는 index 0~ 4 구간 원소를 뒤집는 과정만 추가하면 된다.
즉, 구간의 길이를 구했다면, 그 다음 해당 구간에 대한 reversing을 한다. 그러면 아래와 같이 될 것이다.
{1, 3, 5, 6, 8, 4, 3}
그리고 나서 위 배열에 대해 index 5부터 이진 삽입 정렬을 수행하면 되는 것이다.
위 처럼 기능을 수행하게 되면 역정렬 상태 혹은 정렬 상태에서는 결국 한 번 훑은 뒤, 더이상 이분탐색 할 원소가 없으므로 바로 종료가 된다.
그럼 간단하게 두 메소드를 만들어보자.
먼저, 배열에 대해 index 0부터 정렬되어있는 부분의 구간을 구하는 메소드를 만들어보자.
int getAscending(int[] a, int lo, int hi) {
int limit = lo + 1;
if(limit == hi) { // lo + 1 == hi 라는 것은 결국 정렬 할 원소가 a[lo] 1개 뿐이라는 의미다.
return 1;
}
// 오름차순 일 경우 (안정 정렬을 위해 같은 경우까지 포함)
if(a[lo] <= a[limit]) {
// 오름차순일 때까지 반복한다. (limit이 hi 범위를 벗어나면 안된다.)
while(limit < hi && a[limit - 1] <= a[limit]) {
limit++;
}
}
// 내림차순 일 경우
else {
while(limit < hi && a[limit - 1] > a[limit]) {
limit++;
}
reversing(a, lo, limit);
}
return limit - lo;
}
보시다시피 lo와 lo + 1 의 비교를 통해 오름차순인지 내림차순인지를 구별하고, 그에 따라 정렬되어있는 길이를 구하면 된다.
문제는 우리는 '안정 정렬'을 해야하기 때문에 오름차순 뿐만 아니라 원소가 중복되어 같은 값을 가질 때도 오름차순으로 보아야 한다.
만약 내림차순으로 판단하게 된다면 연속 된 중복 원소가 reversing 메소드에 의해 위치가 서로 바뀌게 되는데 그 순간 이미 안장정렬이 아니게 되어버리기 때문이다. 이 부분만 유의하도록 하자.
그리고 한 가지 의문이 들 수도 있다.
"왜 limit - lo를 해주죠?"
사실 당장은 '전체 배열'에 대해 정렬하는 예시라 index 0 부터 시작하기 때문에 limit만 반환해주어도 당장은 문제가 없지만, 이후 구현 될 Tim Sort에서는 블록 별로 이진 삽입 정렬이 시행된다. 그렇기 때문에 시작점 lo를 빼주지 않으면 반환 되는 값은 정렬 된 구간이 아니라 정렬 된 구간의 오른쪽 끝 인덱스를 가리키는 값이 되어버린다.
그렇기 때문에 좀 더 일반화 하여 특정 시작점에서의 정렬 된 구간의 길이를 반환 할 수 있도록 lo(시작점)을 빼주도록 하는 것이다.
그리고 다음으로 reversing 메소드를 구현하면 되는데, 이 부분은 크게 어려울게 없다. 그냥 바로 구현 코드를 보도록 하자.
// 원소를 뒤집어준다.
void reversing(int[] a, int lo, int hi) {
// a[lo] <= a[i] < a[hi] 범위이므로 마지막 인덱스는 hi - 1부터 시작된다.
hi--;
while (lo < hi) {
int temp = a[lo];
a[lo] = a[hi];
a[hi] = temp;
lo++;
hi--;
}
}
그러면 이제 필요한 메소드들은 완성 되었다.
위 둘을 어떻게 적용시켜주면 될까? 앞서 말했듯, 정렬하려는 배열의 index 0부터 이미 오름차순으로 되어있는 구간의 '길이'를 반환해준다고 했다.
이 말인 즉, 반환 된 길이 값부터 시작하여 이진 삽입 정렬을 실행하면 된다. 그리하기 위해서 필자는 binaryInsertionSort(int[] a, int size) 메소드를 호출하기 전에 getAscending 메소드를 통해 결과를 먼저 얻을 것이다.
그리고 Tim Sort에서는 일정 구간마다 이진 삽입 정렬을 한다고 했다.
그렇기 때문에 단순히 전체 배열에 대한 정렬이 아닌 특정 구간 내에서도 정렬 할 수 있도록 좀 더 일반화 하여 파라미터를 약간 수정하도록 하겠다.
binaryInsertionSort(int[] a, int size) 에서 어디서부터 이분 탐색을 하면 되는지를 가리키는 파라미터 하나를 더 추가하여 해당 값부터 탐색하도록 수정해보겠다.
public class BinaryInsertionSort {
public static void binaryInsertionSort(int[] a) {
if(a.length < 2) {
return;
}
int incLength = getAscending(a, 0, a.length);
binaryInsertionSort(a, 0, a.length, incLength);
}
/**
*
* @param a 정렬 할 배열
* @param lo 정렬 할 배열 구간의 하한선(a[lo] 포함)
* @param hi 정렬 할 배열 구간의 상한선(a[hi] 미포함)
* @param start 정렬 할 배열의 원소 탐색 시작점
*/
private static void binaryInsertionSort(int[] a, int lo, int hi ,int start) {
// 만약 start와 lo가 같다면 이분 탐색 시작점은 lo + 1부터이므로 start을 1 증가시킨다.
if(lo == start) {
start++;
}
/*
* start 이전 원소들은 이미 오름차순으로 정렬 된 상태이므로
* start부터 시작하여 이분 탐색 및 시프팅을 통해 삽입정렬을 해준다.
*/
for (; start < hi; start++) {
// 타겟 넘버
int target = a[start];
int loc = binarySearch(a, target, lo, start);
int j = start - 1;
// 타겟이 들어갈 위치보다 큰 원소들을 뒤로 미룬다.
while (j >= loc) {
a[j + 1] = a[j]; // 이전 원소를 한 칸씩 뒤로 미룬다.
j--;
}
/*
* 위 반복문에서 탈출 하는 경우 앞의 원소가 타겟보다 작다는 의미이므로
* 타겟 원소는 j번째 원소 뒤에 와야한다. 그러므로 타겟은 j + 1 에 위치하게 된다.
*/
a[loc] = target;
}
}
// 이분 탐색
private static int binarySearch(int[] a, int key, int lo, int hi) {
int mid;
while (lo < hi) {
mid = lo + ((hi - lo) / 2);
// 안장 정렬을 위해 key가 a[mid]보다 작을 때만 상한선을 옮긴다.
if (key < a[mid]) {
hi = mid;
}
else {
lo = mid + 1;
}
}
return lo;
}
// lo 부터 몇 개의 원소가 오름차순 혹은 내림차순인지를 반환하는 메소드
private static int getAscending(int[] a, int lo, int hi) {
int limit = lo + 1;
if (limit == hi) { // lo + 1 == hi 라는 것은 결국 정렬 할 원소가 a[lo] 1개 뿐이라는 의미다.
return 1;
}
// 오름차순 일 경우 (안정 정렬을 위해 같은 경우까지 포함)
if (a[lo] <= a[limit]) {
// 오름차순일 때까지 반복한다. (limit이 hi 범위를 벗어나면 안된다.)
while (limit < hi && a[limit - 1] <= a[limit]) {
limit++;
}
}
// 내림차순 일 경우
else {
while (limit < hi && a[limit - 1] > a[limit]) {
limit++;
}
reversing(a, lo, limit); // 내림차순의 경우엔 오름차순으로 변경해주어야 함
}
return limit - lo;
}
// 원소를 뒤집어준다.
private static void reversing(int[] a, int lo, int hi) {
// a[lo] <= a[i] < a[hi] 범위이므로 마지막 인덱스는 hi - 1부터 시작된다.
hi--;
while (lo < hi) {
int temp = a[lo];
a[lo] = a[hi];
a[hi] = temp;
lo++;
hi--;
}
}
}
- 이진 삽입 정렬의 장점 및 단점
[장점]
1. 추가적인 메모리 소비가 작다.
2. 비교 비용이 비싸질 수록 삽입 정렬에 비해 빨라진다.
3. 안장정렬이 가능하다.
4. 추가 구현을 통해 최상의 경우 O(N)의 시간복잡도를 갖게 된다.
[단점]
1. 항상 삽입정렬보다 빠른 것은 아니다.
2. 평균 시간 복잡도는 삽입정렬과 동일하게 O(N2) 이다.
시간복잡도에 대해 잠깐 언급하자면, 기본적으로 삽입정렬과 동일하게 시프팅 비용으로 인해 O(N2)의 시간복잡도를 보인다.
다만, 차이점이라면 앞서 일반적인 삽입 정렬의 경우 정렬 되어있는 상태일 경우에 while() 반복문이 loop를 돌지 않기 때문에 최상의 경우 O(N)의 시간 복잡도를 보이나, 이진 삽입 정렬의 경우 별도의 이분탐색 시간을 갖고 있기 때문에 정렬 되어있는 상태더라도 logN의 비용이 매 번 발생한다.
그렇기 때문에 이진 삽입 정렬의 경우 최상의 경우 O(NlogN)의 시간 복잡도를 보인다.
이는 삽입정렬의 최상의 경우의 시간복잡도 이점을 버리게 되는 것이기 때문에 추가 구현을 통해 우리는 정렬 되어있는 상태에서 O(N)의 시간복잡도를 갖을 수 있도록 만들었다.
추가구현을 하지 않은 이진 삽입 정렬이더라도 삽입 정렬 메커니즘 자체가 시프팅 비용이 상대적으로 적기 때문에 평균 시간복잡도가 O(N2) 인 정렬 알고리즘 중에서는 빠른편에 속하는 알고리즘이다.
- 정리
왜 이렇게 Tim Sort(팀 정렬)에 대해 언급하는지 의문이 들 수 있을 것 같다.
일단, Tim Sort에 대한 구체적 설명은 이후 팀 정렬을 구현 할 때 설명을 하겠지만, 일단 간단하게나마 말하자면 일정 크기 이하의 블럭에 대해 이진 삽입 정렬을 시행하고, 그렇게 정렬 된 부분 리스트끼리 병합하는 과정을 거친다.
단, 이진 삽입 정렬이 시행 되기 전 최대한 '병합 횟수'를 줄이기 위해 오름차순, 혹은 내림차순 블록을 최대한 키워서 해당 블럭을 더한 범위에 대해 이진 삽입 정렬을 할 수 있도록 만든다. 그래서 필자가 심화 구현을 통해 오름차순, 혹은 내림차순의 길이를 구하는 메소드를 만들고 이를 활용 하는 방법을 보여준 것이다.
이 때 만약 모두 정렬 된 상태라면 한 개의 블럭만 생성이 될 것이고, 이는 최소 블럭 크기보다 클 수밖에 없기 때문에 삽입정렬을 시행하지 않고 바로 병합작업으로 넘어가는데 병합 할 블럭도 1개라 그대로 정렬이 끝나버린다.
사실 이렇게 글로만 설명하면 이해하기 어려울 것이라 생각이 들지만, 일단 최소한의 개념만 대략적이나마 알고있으면 도움이 될 거 같아 일단 적어두기로 했다.
이후 Tim Sort를 배울 때 위에서 설명한 개념들을 다루게 되니 잘 기억해두시길 바란다.
이 번 포스팅의 경우 사실 비교(정렬)하고자 하는 데이터의 특성에 따라 차이가 발생하기 때문에 따로 시간측정은 하지 않았다. 다만 정리하자면, 비교비용이 비쌀수록 이진 삽입 정렬이 삽입 정렬에 비해 성능이 좋아진다는 것이다.
각 정렬 알고리즘 별 시간 복잡도와 평균 정렬 속도는 다음과 같다. (일반적인 삽입 정렬과 크게 다르진 않으므로 삽입정렬을 기준으로 보아도 괜찮을 것 같다.)

혹여 부족한 부분이 있거나 궁금한 점, 모르거나 이해가 가지 않는 부분이 있다면 언제든 댓글 달아주시면 감사하겠다.
그 외에 필자가 여러 타입들에 대해 구현 한 정렬 알고리즘 소스 코드들을 자세히 보고싶다면 아래 깃허브 repo에 업로드되어있으니 이를 참고하시길 바란다.
https://github.com/kdgyun/Sorting_Algorithm.git
kdgyun/Sorting_Algorithm
Contribute to kdgyun/Sorting_Algorithm development by creating an account on GitHub.
github.com
'알고리즘 > Java' 카테고리의 다른 글
| 자바 [JAVA] - 팀 정렬 (Tim Sort) (10) | 2021.11.02 |
|---|---|
| 자바 [JAVA] - 퀵 정렬 (Quick Sort) (29) | 2021.05.19 |
| 자바 [JAVA] - 합병정렬 / 병합정렬 (Merge Sort) (24) | 2021.03.31 |
| 자바 [JAVA] - 힙 정렬 (Heap Sort) (31) | 2021.03.14 |
| 자바 [JAVA] - 셸 정렬 (Shell Sort) (18) | 2021.02.18 |