[백준] 17298번 : 오큰수 - JAVA [자바]
17298번: 오큰수
첫째 줄에 수열 A의 크기 N (1 ≤ N ≤ 1,000,000)이 주어진다. 둘째에 수열 A의 원소 A1, A2, ..., AN (1 ≤ Ai ≤ 1,000,000)이 주어진다.
www.acmicpc.net
- 문제

Stack의 원리를 이해하면 생각보다 그리 어렵지는 않다.
- 알고리즘 [접근 방법]
이 문제가 의외로 어떻게 스택을 활용해야할지 갈피를 못잡는 문제인 것 같다.
이중 for문을 사용하면 최대 1,000,000 * 1,000,000 = 1,000,000,000,000 (1조)으로 시간초과 날 것이 뻔하다.
스택의 기본 원리는 딱 한 가지만 기억하면 된다. '후입선출' 즉, 가장 최근에 들어온 것이 가장 먼저 나오는 것이다. 스택수열을 풀어보았다면 이 문제도 스택수열과 비슷한 원리라고 이해하면 된다.
일단 문제를 이해해보자.
오큰수(NEG)는 현재 원소보다 큰 수 중 가장 왼쪽에 있는 원소를 의미한다. 위 문제에서 나와있는 예시로 들면 이렇다.
{3, 5, 2, 7} 이라는 수열이 있을 때,
3 보다 큰 수(5, 7) 중 가장 왼쪽에 있는 수는 5다.
5 보다 큰 수(7) 중 가장 왼쪽에 있는 수는 7이다.
2 보다 큰 수(7) 중 가장 왼쪽에 있는 수는 7이다.
7 보다 큰 수(∅) 중 가장 왼쪽에 있는 수는 존재하지 않으므로 -1이다.
이를 어떻게 스택을 이용해야 할까?
바로 수열을 탐색하면서 현재 원소가 이전의 원소보다 작을 때 까지 stack에 수열의 index를 stack에 추가(push) 하는 것이다. 그리고 만약 현재 원소가 스택의 top 원소를 인덱스로 하는 수열의 원소보다 크게 될 경우 stack의 원소를 pop하면서 해당 인덱스에 해당하는 원소들을 현재 원소로 바꿔주는 것이다.
무슨 말인가 이해가 안된다면 위의 두 번째 예제인 seq{9, 5, 4, 8} 을 예로 들어보자.
첫 번째 원소는 이전 원소가 없기 때문에 index 0을 가리키는 0을 스택에 push한다.
push(0index) : stack{0index}
수열(seq)을 index 1부터 탐색
5 (seq[1]) < 9 (seq[stack.peek() = 0]) 이므로 index 1을 스택에 push한다.
→ result : stack{0, 1}, seq{9, 5, 4, 8}
4 (seq[2]) < 5 (seq[stack.peek() = 1]) 이므로 index 2를 스택에 push한다.
→ result : stack{0, 1, 2}, seq{9, 5, 4, 8}
8 (seq[3]) > 4 (seq[stack.peek() = 2]) 이므로 8보다 큰 수가 나오기 전까지 pop하면서 answer배열을 초기화 한다.
→ 8 (seq[3]) > 4 (seq[stack.peek() = 2]) 이므로 seq[stack.pop() = 2] = 8 (seq[3])
↳ result : stack{0, 1}, seq{9, 5, 8, 8}
→ 8 (seq[3]) > 5 (seq[stack.peek() = 1]) 이므로 seq[stack.pop() = 1] = 8 (seq[3])
↳ result : stack{0}, seq{9, 8, 8, 8}
8 (seq[3]) < 9 (seq[stack.peek() = 0]) 이므로 pop 중단 후 현재 인덱스(index 3)를 stack에 push한다.
↳ result : stack{0, 3}, seq{9, 8, 8, 9}
더이상 탐색할 수열이 없다.
이는 즉, stack에 저장된 seq의 인덱스 값들은 자연스레 해당 인덱스의 값보다 뒤에서 큰 수가 없다는 의미이므로 모두 -1이 된다.
한마디로 stack에 남아있는 index 값은 자연스레 -1 값이 되는 index를 가리키게 되는 것이다.
seq[stack.pop() = 3] = -1
↳ result : stack{0}, seq{9, 8, 8, -1}
seq[stack.pop() = 0] = -1
↳ result : stack{}, seq{-1, 8, 8, -1}
최종적으로 {-1, 8, 8, -1} 이 정답이 되는 것이다.
그림으로 한 번 보도록 하자

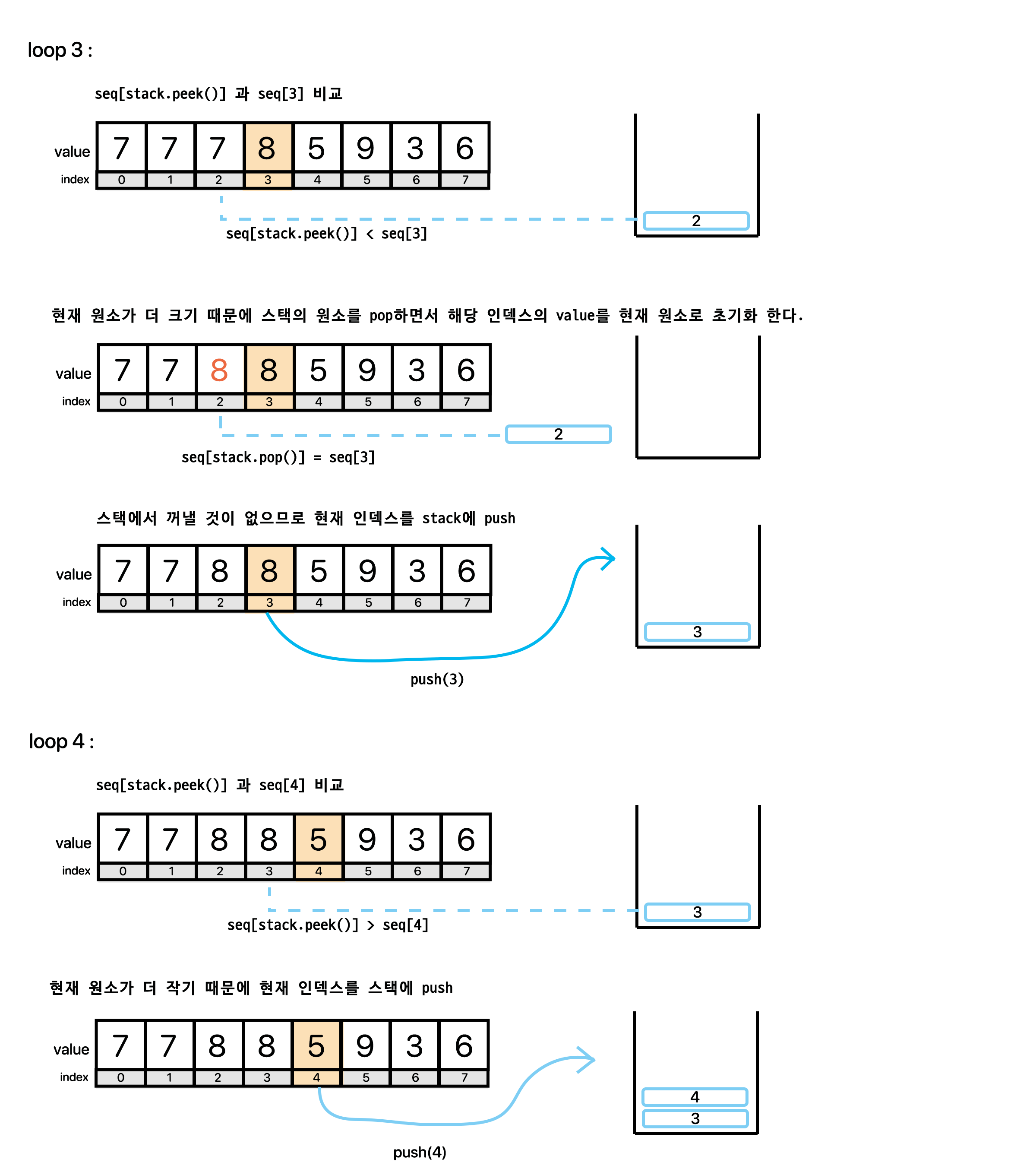


그림이 조금 길긴 하지만,, 과정 하나씩 본다면 아마 이해하실 수 있을 것이다.
위의 과정을 토대로 다음과 같이 탐색과정을 코드를 짤 수 있다.
Stack<Integer> stack;
int[] seq; // 입력받은 값으로 초기화 되었다고 가정
for(int i = 0; i < seq.length; i++) {
/*
* 스택이 비어있지 않으면서
* 현재 원소가 스택의 맨 위 원소가 가리키는 원소보다 큰 경우
* 해당 조건을 만족할 때 까지 stack의 원소를 pop하면서
* 해당 인덱스의 값을 현재 원소로 바꿔준다.
*/
while(!stack.empty() && seq[stack.peek()] < seq[i]) {
seq[stack.pop()] = seq[i];
}
stack.push(i);
}
// 위 반복문이 끝나면 스택에 있는 모든 요소들을 pop하면서 -1로 초기화한다.
while(!stack.emtpy()) {
seq[stack.pop()] = -1;
}
이를 토대로 코드를 작성하면 된다.
- 4가지 방법을 사용하여 풀이한다.
이번 문제는 Java에서는 Stack 클래스를 이용하거나, 스택처럼 활용할 수 있는 배열을 만들어 활용할 수 있기에 이 두 가지를 토대로 Scanner 입력방법과 BufferedReader 입력방법을 비교해보고자 한다.
출력량이 워낙 많다보니 필자는 네 가지 모두 StringBuilder을 이용할 것이지만, BufferedWriter가 편하신 분들은 BufferedWriter을 쓰셔도 된다.
1. Scanner + Stack
2. Scanner + array
3. BufferedReader + Stack
4. BufferedReader + array
- 풀이
- 방법 1 : [Scanner + Stack]
import java.util.Scanner;
import java.util.Stack;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
Stack<Integer> stack = new Stack<Integer>();
int N = in.nextInt();
int[] seq = new int[N];
for(int i = 0; i < N; i++) {
seq[i] = in.nextInt();
}
for(int i = 0; i < N; i++) {
/*
* 스택이 비어있지 않으면서
* 현재 원소가 스택의 맨 위 원소가 가리키는 원소보다 큰 경우
* 해당 조건을 만족할 때 까지 stack의 원소를 pop하면서
* 해당 인덱스의 값을 현재 원소로 바꿔준다.
*/
while(!stack.isEmpty() && seq[stack.peek()] < seq[i]) {
seq[stack.pop()] = seq[i];
}
stack.push(i);
}
/*
* 스택의 모든 원소를 pop하면서 해당 인덱스의 value를
* -1로 초기화한다.
*/
while(!stack.isEmpty()) {
seq[stack.pop()] = -1;
}
StringBuilder sb = new StringBuilder();
for(int i = 0; i < N; i++) {
sb.append(seq[i]).append(' ');
}
System.out.println(sb);
}
}
Stack 자료구조가 Java에서 이미 지원하고 있어 가장 어렵지 않게 짤 수 있는 방법이라 할 수 있겠다.
- 방법 2 : [Scanner + array]
Stack 클래스를 따로 쓰지 않고 가장 기본적인 원리만 적용하여 하나의 배열을 생성해 Stack처럼 사용하는 방식이다. 크게 필요한 것은 int[] 배열과, 가장 맨 위의 원소를 가리키는 top 이라는 변수 두 개만 있으면 된다.
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int N = in.nextInt();
int[] seq = new int[N];
int[] stack = new int[N]; // 스택처럼 쓸 배열
int top = -1; // 스택의 맨 위 원소를 가리키는 변수
for (int i = 0; i < N; i++) {
seq[i] = in.nextInt();
}
for (int i = 0; i < N; i++) {
/*
* 스택이 비어있지 않으면서 (= top 이 -1이 아닐 경우)
* 현재 원소가 스택의 맨 위 원소가 가리키는 원소보다 큰 경우
* 해당 조건을 만족할 때 까지 stack의 원소를 pop하면서
* 해당 인덱스의 값을 현재 원소로 바꿔준다.
*/
while (top != - 1 && seq[stack[top]] < seq[i]) {
seq[stack[top]] = seq[i];
top--;
}
top++;
stack[top] = i;
}
/*
* 스택의 모든 원소를 pop하면서 해당 인덱스의 value를
* -1로 초기화한다.
*/
for(int i = top; i >= 0; i--) {
seq[stack[i]] = -1;
}
StringBuilder sb = new StringBuilder();
for (int v : seq) {
sb.append(v).append(' ');
}
System.out.println(sb);
}
}
생각보다 엄청 간단해보이지 않는가..?
- 방법 3 : [BufferedReader + Stack]
입력 방법을 Scanner 대신 BufferedReader 을 사용하여 풀이하는 방법이다. 입력 방식을 제외하고는 방법 1과 같다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.util.StringTokenizer;
import java.util.Stack;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
Stack<Integer> stack = new Stack<Integer>();
int N = Integer.parseInt(br.readLine());
int[] seq = new int[N];
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
for(int i = 0; i < N; i++) {
seq[i] = Integer.parseInt(st.nextToken());
}
for(int i = 0; i < N; i++) {
/*
* 스택이 비어있지 않으면서
* 현재 원소가 스택의 맨 위 원소가 가리키는 원소보다 큰 경우
* 해당 조건을 만족할 때 까지 stack의 원소를 pop하면서
* 해당 인덱스의 값을 현재 원소로 바꿔준다.
*/
while(!stack.isEmpty() && seq[stack.peek()] < seq[i]) {
seq[stack.pop()] = seq[i];
}
stack.push(i);
}
/*
* 스택의 모든 원소를 pop하면서 해당 인덱스의 value를
* -1로 초기화한다.
*/
while(!stack.isEmpty()) {
seq[stack.pop()] = -1;
}
StringBuilder sb = new StringBuilder();
for(int i = 0; i < N; i++) {
sb.append(seq[i]).append(' ');
}
System.out.println(sb);
}
}
- 방법 4 : [BufferedReader + array]
마지막으로 Stack 클래스 대신 배열을 사용하여 풀이한 방법이다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
int[] seq = new int[N];
int[] stack = new int[N]; // 스택처럼 쓸 배열
int top = -1; // 스택의 맨 위 원소를 가리키는 변수
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
for (int i = 0; i < N; i++) {
seq[i] = Integer.parseInt(st.nextToken());
}
for (int i = 0; i < N; i++) {
/*
* 스택이 비어있지 않으면서 (= top 이 -1이 아닐 경우)
* 현재 원소가 스택의 맨 위 원소가 가리키는 원소보다 큰 경우
* 해당 조건을 만족할 때 까지 stack의 원소를 pop하면서
* 해당 인덱스의 값을 현재 원소로 바꿔준다.
*/
while (top != - 1 && seq[stack[top]] < seq[i]) {
seq[stack[top]] = seq[i];
top--;
}
top++;
stack[top] = i;
}
/*
* 스택의 모든 원소를 pop하면서 해당 인덱스의 value를
* -1로 초기화한다.
*/
for(int i = top; i >= 0; i--) {
seq[stack[i]] = -1;
}
StringBuilder sb = new StringBuilder();
for (int v : seq) {
sb.append(v).append(' ');
}
System.out.println(sb);
}
}
- 성능

채점 번호 : 25519611 - 방법 4 : BufferedReader + array
채점 번호 : 25519602 - 방법 3 : BufferedReader + Stack
채점 번호 : 25519593 - 방법 2 : Scanner + array
채점 번호 : 25519588 - 방법 1 : Scanner + Stack
입력의 경우는 확실히 Scanner 보다는 BufferedReader 가 빠른 걸 볼 수 있다. 그리고 아무래도 Stack클래스의 경우 내부에서는 Object[]배열로 되어있고 상대적으로 많은 검사를 하는 등, 구조가 복잡하기 때문에 딱 필요한 부분만 구현하는 array방식이 좀 더 빠르다는 것을 볼 수 있다.
- 정리
생각보다 이 번 풀이를 보면 코드도 복잡하지 않고 전체적으로 정말 별 거 없어보인다.
다만, 이렇게 까지 알고리즘을 구현하기 위해 스택의 원리와 과정을 이해하고 있어야 문제를 보고 어떤 부분에 적용할 수 있을지를 떠올릴 수 있는 문제가 아닐까 싶다.
이 번 문제의 경우 글로만 설명하기에는 이해를 못할 것 같은 부분이 있는 것 같아 오랜만에 포토샵으로 작업을 해보았다.
만약 어렵거나 이해가 되지 않은 부분이 있다면 언제든 댓글 남겨주시면 최대한 빠르게 답변드리겠다.
'JAVA - 백준 [BAEK JOON] > 기타 문제' 카테고리의 다른 글
| [백준] 2261번 : 가장 가까운 두 점 - JAVA [자바] (4) | 2021.06.26 |
|---|---|
| [백준] 15236번 : Dominos - JAVA [자바] (0) | 2020.11.01 |
| [백준] 11653번 : 소인수분해 - JAVA [자바] (3) | 2020.10.18 |
| [백준] 1003번 : 피보나치 함수 - JAVA [자바] (24) | 2020.07.22 |
| [백준] 2748번 : 피보나치 수 2 - JAVA [자바] (6) | 2020.07.21 |