[백준] 2740번 : 행렬 곱셈 - JAVA [자바]
2740번: 행렬 곱셈
첫째 줄에 행렬 A의 크기 N 과 M이 주어진다. 둘째 줄부터 N개의 줄에 행렬 A의 원소 M개가 순서대로 주어진다. 그 다음 줄에는 행렬 B의 크기 M과 K가 주어진다. 이어서 M개의 줄에 행렬 B의 원소 K개
www.acmicpc.net
- 문제

이 문제가 원래 생각없이 일반적인 행렬 곱셈 방식으로 풀어서 통과했지만.. 분할 정복 카테고리에 들어있어서 어떻게 분할정복으로 풀이해야 할지 많이 고민했던 문제다.
- 알고리즘 [접근 방법]
문제 자체는 어렵지 않을 것이다. 행렬 곱셈을 그대로 구현해주어도 통과가 되니...
근데 이를 어떻게 분할정복으로 풀지? 라는 고민으로 찾아오신 분들도 꽤 많을 것이다. 필자도 똑같은 고민을 했는데, 알고보니 스트라센 알고리즘(Strassen Algorithm)을 사용하라는 것이였다.
그렇기에 두 가지 방법을 설명하고자 한다. 가장 먼저 기본적인 행렬 곱셈 알고리즘을 보여준 뒤, 스트라센 행렬 곱셈 풀이 방법을 보여줄 것이다.
[기본적인 행렬 곱셈]
대부분 많은 분들은 두 행렬의 곱셈을 어떻게 하는지는 알고 있을 것이다.
예로들면 다음과 같을 것이다.
[A(2x2) B(2x2)]

[A(2x3) B(3x2)]

이러한 연산을 좀 더 간략하게 표현하자면 이렇다.

즉, 두 행렬이 들어 올 떄, A의 행과 B의 열을 순서대로 반복하면서 곱셈을 해주면 된다.
그리고 보면 알겠지만, n×m 크기의 A행렬과 m×k 크기의 B행렬의 곱은 n×k 크기의 행렬로 반환이 된다는 것을 알아두시길 바란다.
이를 토대로 알고리즘을 짜면 다음과 같다.
int[][] A = new int[N][M]; // N x M 크기의 행렬
int[][] B = new int[M][K]; // M x K 크기의 행렬
int[][] C = new int[N][K]; // AxB의 행렬을 담을 N x K 크기의 행렬
for(int i = 0; i < N; i++) { // i = A행렬의 i번째 row
for(int j = 0; j < K; j++) { // j = B행렬의 j번째 col
/*
* A의 row(i)와 B의 col(j)의 각 원소들을 곱한 뒤 더하는 과정
*
* ex) A(row1) = [a b c], B(col1) = [g h i]
* --> = (ab + bh + ci)
*/
for(int k = 0; k < M; k++) { // 더해주는 원소의 개수는 총 M개다.
// A의 i번째 row의 k번째 열 원소와, B의 j번째 col의 k번째 행 원소를 곱한 뒤 누적합
C[i][j] += A[i][k] * B[k][j];
}
}
}
위 알고리즘이 끝이다.
물론 메모리 구조와 캐시에 대한 이해가 있으신 분은 위와 같은 행렬 곱의 연산에서 row를 기준으로 움직이면 메모리 참조 할 때 연속성 있게 참조되지 않고 jump되는 과정이 많아져 성능상 효율적이지 않은 걸 아실 것이다.
그래서 좀 더 캐시 친화적인 코드로 작성하자면 다음과 같다.
int[][] A = new int[N][M]; // N x M 크기의 행렬
int[][] B = new int[M][K]; // M x K 크기의 행렬
int[][] C = new int[N][K]; // AxB의 행렬을 담을 N x K 크기의 행렬
for (int k = 0; k < M; k++) {
for (int i = 0; i < N; i++) {
// A(ik) 원소를 고정시켜두고, 그에 대한 B의 k열을 고정시켜 j행을 움직이면서 연산한다.
r = A[i][k];
for (int j = 0; j < K; j++) {
res[i][j] += r * B[k][j];
}
}
}
즉, 연산 순서를 약간 변형시킨 것이다.
왜 위 코드가 성능이 좀 더 좋은지는 이 번에 스트라센 알고리즘까지 다루기엔 그 양이 너무 많기에, 일단 따로 설명은 해드리진 않겠다.
한 번 여러분이 임의의 두 행렬을 메모리를 그려서 순서대로 두 방식이 어떻게 참조가 되는지를 보면 좋을 것이다.
나중에 기회가 되면 이 부분을 따로 다루기로 하겠다.
[스트라센 알고리즘 (Strassen Alogrithm)]
위 방법으로도 풀리지만, 이 번 문제가 분할 정복 카테고리에 있는 만큼 분할 정복으로도 풀어보아야 하지 않겠는가.
일단 스트라센 알고리즘에 대해 위키백과에서도 자세히 설명하고 있으니, 필자가 정리 한 것이 잘 이해가 안된다면 아래 글을 참고하셔도 좋을 것이다. (여기서는 슈트라센이라고 한다. 뭐가 되었던..)
슈트라센 알고리즘 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 선형대수학에서 슈트라센 알고리즘은 독일의 수학자 폴커 슈트라센(Volker Strassen)이 1969년에 개발한 행렬 곱셈 알고리즘이다. 정의에 따라 n×n 크기의 두 행렬을
ko.wikipedia.org
위 위백과에 보면 다음과 같이 써있다.

이게 무슨 말인고 하니..
일단, 조건이 있다는 것이다. A와 B 행렬은 정사각행렬이며 모두 2n × 2n 크기어야 한다는 것이다. 만약 그렇지 않다면 모자라는 행과 열을 0으로 채운다는 것이다.
그리고 가장 이해하기 쉽게 두 행렬은 같은 크기로 맞춰주도록 한다.
예로들어 다음과 같이 두 행렬이 주어졌다고 해보자.

위 행렬 A, B 모두 2n 꼴이 아니다. 그렇기 때문에 두 행렬을 모두 2n 꼴로 만들어주는 것이다. 가장 2n에 가까운 값은 4이니, 4×4 꼴로 다음과 같이 만들어주는 것이다.

이렇게 조건을 만족하도록 맞춰주었으면 이제 다음 과정을 살펴보아야 한다.
보면, A와 B, C 행렬을 같은 크기의 정사각행렬로 쪼개야 한다고 되어있다. 즉, 위 예시를 토대로 보자면, 다음과 같다.
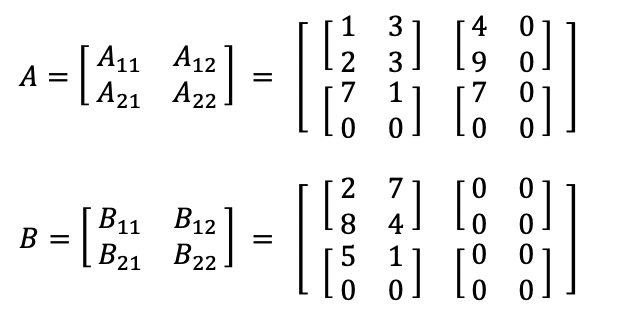
그리고 만약, 위 A와 B의 곱을 일반적인 행렬 곱으로 표현한다면 다음과 같을 것이다.

위 과정을 정리하자면 이렇다.
1. A와 B행렬 곱을 한다.
2. A와 B행렬을 부분행렬로 나눈다.
3. A의 부분행렬과 B의 부분행렬의 곱이 발생하므로 부분행렬의 곱에 대해 1번 과정으로 돌아간다.
이렇게 재귀적으로 분할 정복을 이용 할 수 있다.
무슨 말인지 이해가 안된다면 다음 그림을 보고 이해를 해보도록 하자.
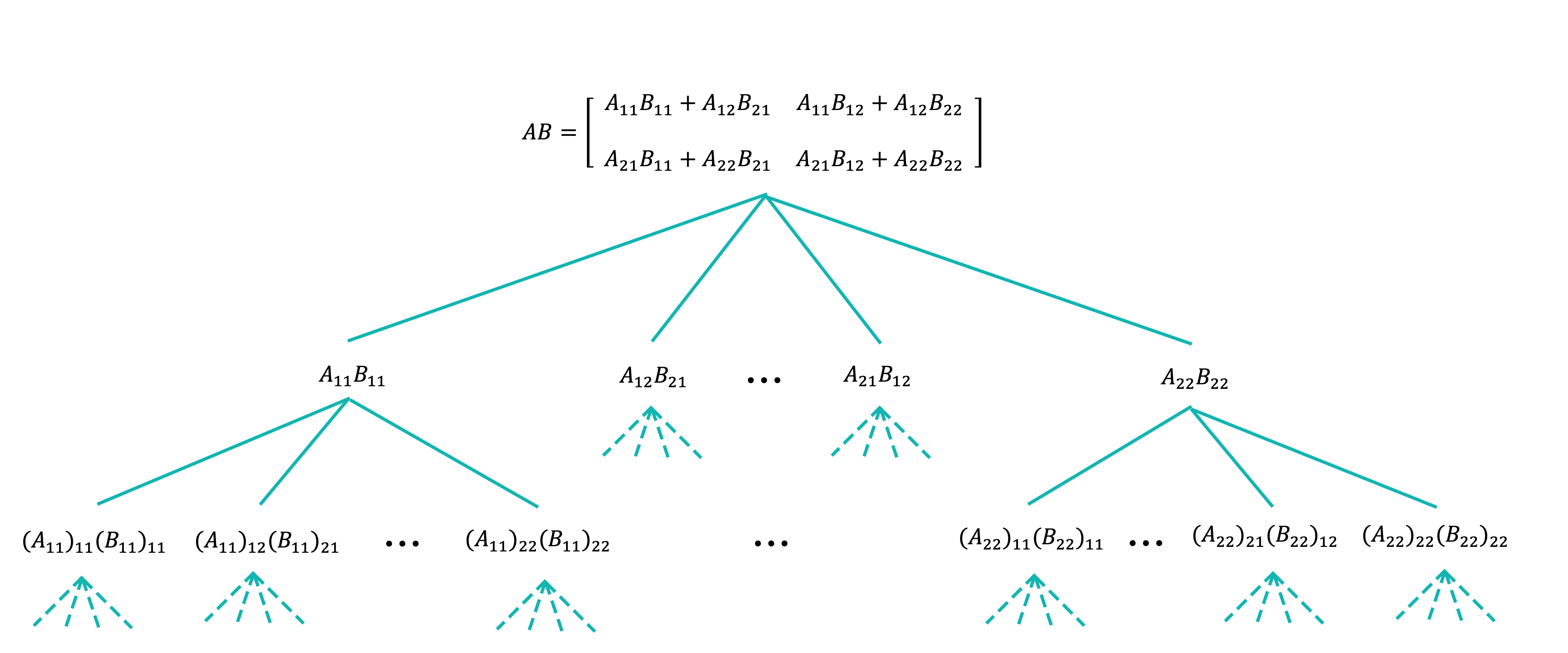
이런식으로 부분행렬에 대한 곱을 분할 정복으로 풀어내면 된다.
대강 코드를 짜보자면 다음과 같을 것이다.
// 정사각행렬로 padding 되기 때문에 행과 열이 같은 2^n의 size를 갖는다.
static int[][] multiply(int[][] A, int[][] B, int size) {
int[][] C = new int[size][size]; // 완성시킬 C 배열
// size가 1로 가장 작게 쪼개질 경우 (0,0) 원소밖에 없으므로 해당 원소의 곱을 반환
if(size == 1) {
C[0][0] = A[0][0] * B[0][0];
return C;
}
int newSize = size / 2; // 부분행렬에 대한 사이즈
// A의 부분행렬
int[][] a11 = subArray(A, 0, 0, newSize);
int[][] a12 = subArray(A, 0, newSize, newSize);
int[][] a21 = subArray(A, newSize, 0, newSize);
int[][] a22 = subArray(A,newSize, newSize, newSize);
// A의 부분행렬
int[][] b11 = subArray(B, 0, 0, newSize);
int[][] b12 = subArray(B, 0, newSize, newSize);
int[][] b21 = subArray(B, newSize, 0, newSize);
int[][] b22 = subArray(B, newSize, newSize, newSize);
// multiply 분할정복
// c11 = a11*b11 + a12*b21
int[][] c11 = add(multiply(a11, b11, newSize), multiply(a12, b21, newSize), newSize);
// c12 = a11*b12 + a12*b22
int[][] c12 = add(multiply(a11, b12, newSize), multiply(a12, b22, newSize), newSize);
// c21 = a21*b11 + a22*b21
int[][] c21 = add(multiply(a21, b11, newSize), multiply(a22, b21, newSize), newSize);
// c21 = a21*b12 + a22*b22
int[][] c22 = add(multiply(a21, b12, newSize), multiply(a22, b22, newSize), newSize);
// 구해진 C의 부분배열 4개를 하나의 C배열로 합친다.
merge(c11, C, 0, 0, newSize);
merge(c12, C, 0, newSize, newSize);
merge(c21, C, newSize, 0, newSize);
merge(c22, C, newSize, newSize, newSize);
// 완성된 배열 리턴
return C;
}
// 부분 배열을 얻는 메소드
static int[][] subArray(int[][] src, int row, int col, int size) {
int[][] dest = new int[size][size];
for (int dset_i = 0, src_i = row; dset_i < size; dset_i++, src_i++) {
for (int dest_j = 0, src_j = col; dest_j < size; dest_j++, src_j++) {
dest[dset_i][dest_j] = src[src_i][src_j];
}
}
return dest;
}
// 두 배열의 덧셈
static int[][] add(int[][] A, int[][] B, int size) {
int[][] C = new int[size][size];
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
C[i][j] = A[i][j] + B[i][j];
}
}
return C;
}
// src는 복사할 배열(=부분배열), dest는 합쳐질 배열(= 배열 C)
public static void merge(int[][] src, int[][] dest, int row, int col, int size) {
for (int src_i = 0, dest_i = row; src_i < size; src_i++, dest_i++) {
for (int src_j = 0, dest_j = col; src_j < size; src_j++, dest_j++) {
dest[dest_i][dest_j] = src[src_i][src_j];
}
}
}
하지만, 좀만 생각해보자. AB행렬의 곱을 보면 부분행렬의 곱이 총 8번 일어난다. 그리고 부분 행렬에 대한 부분행렬의 곱 또한 8번이 일어날 것이다. 결과적으로 전체적인 프로세스는 아직까지 우리가 앞서 했던 일반적인 행렬 곱과 별반 다르지 않다.
그래서 Strassen 알고리즘에서 중요한 것은 C11 C12 C21 C22 에 위치하는 A와 B 행렬의 부분행렬 곱 연산 과정을 재정의 하는 것이다.
위키백과 글을 보면 다음과 같이 말하고 있다.

즉, 우리가 앞서 했던 일반적인 행렬 곱인 A행렬의 부분행렬과 B행렬의 부분행렬 곱이 아닌 A의 부분행렬과 B의 부분행렬의 연산을 새롭게 따로 연산하여 7개의 M 행렬로 나타내고, 그 행렬들을 덧셈 및 뺄셈을 통해 각 자리에 맞는 행렬 값을 구하는 것이다.
위를 보면 오히려 복잡해진 것 같지만, 잘 보면, 두 행렬의 곱셈 연산이 7번, 즉 서브트리를 7개만 갖는다는 것이다.
우리가 구현해야 할 건 앞서 일반적인 분할 정복에서 썼던 메소드들(subArray, add, merge)에 뺄셈 메소드만 구현하면 된다. 이 부분은 엄청 간단 할 것이다.
행렬 곱셈만 뺴고 기본적으로 필요한 메소드를 하나하나 확인해보자.
// 행렬 뺄셈
static int[][] sub(int[][] A, int[][] B, int size) {
int[][] C = new int[size][size];
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
C[i][j] = A[i][j] - B[i][j];
}
}
return C;
}
// 행렬 덧셈
static int[][] add(int[][] A, int[][] B, int size) {
int n = size;
int[][] C = new int[n][n];
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
C[i][j] = A[i][j] + B[i][j];
}
}
return C;
}
// 부분행렬을 반환하는 메소드
static int[][] subArray(int[][] src, int row, int col, int size) {
int[][] dest = new int[size][size];
for (int dset_i = 0, src_i = row; dset_i < size; dset_i++, src_i++) {
for (int dest_j = 0, src_j = col; dest_j < size; dest_j++, src_j++) {
dest[dset_i][dest_j] = src[src_i][src_j];
}
}
return dest;
}
// src는 복사할 배열(=부분배열), dest는 합쳐질 배열(= 배열 C)
public static void merge(int[][] src, int[][] dest, int row, int col, int size) {
for (int src_i = 0, dest_i = row; src_i < size; src_i++, dest_i++) {
for (int src_j = 0, dest_j = col; src_j < size; src_j++, dest_j++) {
dest[dest_i][dest_j] = src[src_i][src_j];
}
}
}
그리고 이제 행렬 곱을 하는 메소드를 위 과정에 맞게 구현해보자.
전체적인 골격은 일반적인 분할정복 코드와 유사한데, M1, M2, M3, M4, M5, M6, M7 를 통해 연산과정만 추가해주면 된다.
(위로 스크롤하면서 보기 힘들테니 다시 한 번 첨부하겠다.)
위 연산 과정을 그대로 작성해주면 된다. 자세한 건 코드를 보면서 확인해보자.
public static int[][] multiply(int[][] A, int[][] B, int size) {
int[][] C = new int[size][size]; // 완성시킬 C 배열
// size가 1로 가장 작게 쪼개질 경우 (0,0) 원소밖에 없으므로 해당 원소의 곱을 반환
if (size == 1) {
C[0][0] = A[0][0] * B[0][0];
return C;
}
int newSize = size / 2; // 부분행렬에 대한 사이즈
// A의 부분행렬
int[][] a11 = subArray(A, 0, 0, newSize);
int[][] a12 = subArray(A, 0, newSize, newSize);
int[][] a21 = subArray(A, newSize, 0, newSize);
int[][] a22 = subArray(A,newSize, newSize, newSize);
// B의 부분행렬
int[][] b11 = subArray(B, 0, 0, newSize);
int[][] b12 = subArray(B, 0, newSize, newSize);
int[][] b21 = subArray(B, newSize, 0, newSize);
int[][] b22 = subArray(B, newSize, newSize, newSize);
// M1 := (A11 + A22) * (B11 + B22)
int[][] M1 = multiply(add(a11, a22, newSize), add(b11, b22, newSize), newSize);
// M2 := (A21 + A22) * B11
int[][] M2 = multiply(add(a21, a22, newSize), b11, newSize);
// M3 := A11 * (B12 - B22)
int[][] M3 = multiply(a11, sub(b12, b22, newSize), newSize);
// M4 := A22 * (B21 − B11)
int[][] M4 = multiply(a22, sub(b21, b11, newSize), newSize);
// M5 := (A11 + A12) * B22
int[][] M5 = multiply(add(a11, a12, newSize), b22, newSize);
// M6 := (A21 - A11) * (B11 + B12)
int[][] M6 = multiply(sub(a21, a11, newSize), add(b11, b12, newSize), newSize);
// M7 := (A12 - A22) * (B21−B22)
int[][] M7 = multiply(sub(a12, a22, newSize), add(b21, b22, newSize), newSize);
// C11 := M1 + M4 − M5 + M7
int[][] c11 = add(sub(add(M1, M4, newSize), M5, newSize), M7, newSize);
// C12 := M3 + M5
int[][] c12 = add(M3, M5, newSize);
// C21 := M2 + M4
int[][] c21 = add(M2, M4, newSize);
// C22 := M1 − M2 + M3 + M6
int[][] c22 = add(add(sub(M1, M2, newSize), M3, newSize), M6, newSize);
// 구해진 C의 부분행렬들 합치기
merge(c11, C, 0, 0, newSize);
merge(c12, C, 0, newSize, newSize);
merge(c21, C, newSize, 0, newSize);
merge(c22, C, newSize, newSize, newSize);
return C;
}
위와같이 짜주면 끝이다. (뭔가 복잡해보여도, 위 식을 그대로 작성해주기만 하면 된다.)
그럼 시간 복잡도는 어떻게 될까?
일단, 맨 처음 보았던 반복문을 이용한 행렬의 곱셈의 경우 O(N3)인 것은 대부분 알 것이다.
문제는 분할정복 부분일 것이다.
우리가 구해야 할 것은 '행렬의 곱'이었다. 즉, 분할 정복 과정 자체가 부분 행렬로 쪼개서 그 행렬의 곱을 구하는 것이다.
맨 처음 보여주었던 일반적인 분할 정복의 경우 식이 다음과 같았다.
이 때, 행렬의 크기(=입력의 크기)를 N이라고 할 때 식을 다음과 같이 정의할 수 있다.

여기서 O(N2) 은 덧셈 과정을 말한다. 이는 분할정복 재귀부분과 상관 없이 각 곱셈(재귀)이 풀리면 입력 N에 대해 N×N 사이즈의 행렬 덧셈을 해주어야하기 때문이다. (더하는 횟수 자체는 상수라 무시된다.)
그리고 재귀로 들어가는 부분은 8T(N/2) 인 것이다.
이를 마스터 정리(Master Theorem) 를 이용하면 다음과 같이 나온다.

마스터 정리가 점근적으로 계산하는 것이라 완벽하게 일치한다고 할 순 없지만, 식을 계산하면 결과적으로 일반적으로 반복문을 사용한 행렬 곱과 시간복잡도가 다르지 않다.
반면, 스트라센(슈트라센) 기법을 이용하면, 곱셈은 7번, 덧셈 및 뺄셈은 18번이다.
이를 다시 마스터 정리에 적용하면 다음과 같다.

위 식을 풀면 다음과 같다.

보면 스트라센 알고리즘이 좀 더 좋아보이긴 한다. 하지만 치명적인 단점도 있으니, 이 것은 아래 코드와 결과를 보고서 얘기해보도록 하자.
- 3가지 방법을 사용하여 풀이한다.
이 번 풀이는 모두 BufferedReader 로 입력을 받을 것이다. 이 번 문제만큼은 알고리즘에 중점을 둬서 풀이하려 한다.
그리고 일반적인 분할 정복법으로는 메모리 초과가 뜬다. 이 점만 알아두고 아래 세 가지 방법을 풀이하도록 하겠다.
1. 반복문 방법
2. 스트라센 방법
3. 개선 된 스트라센 방법
- 풀이
- 방법 1 : [반복문 풀이법]
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringBuilder sb = new StringBuilder();
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
// A행렬 입력
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
int[][] A = new int[N][M];
for(int i = 0; i < N; i++) {
st = new StringTokenizer(br.readLine(), " ");
for(int j = 0; j < M; j++) {
A[i][j] = Integer.parseInt(st.nextToken());
}
}
st = new StringTokenizer(br.readLine(), " ");
// B행렬 입력
st.nextToken(); // 어차피 M값으로 같은 수이기 때문에 버려도 상관 없다.
int K = Integer.parseInt(st.nextToken());
int[][] B = new int[M][K];
for(int i = 0; i < M; i++) {
st = new StringTokenizer(br.readLine(), " ");
for(int j = 0; j < K; j++) {
B[i][j] = Integer.parseInt(st.nextToken());
}
}
// 행렬 계산 및 출력
for(int i = 0; i < N; i++) {
for(int j = 0; j < K; j++) {
int sum = 0;
for(int k = 0; k < M; k++) {
sum += A[i][k] * B[k][j];
}
// A의 i행의 j열 연산이 끝나면 바로 출력문으로 보내준다.
sb.append(sum).append(' ');
}
sb.append('\n');
}
System.out.println(sb);
}
}
가장 기본적인 방법이라 할 수 있겠다.
이 부분은 크게 설명할 건 없으니 바로 넘어가도록 하겠다.
- 방법 2 : [스트라센 방법]
필자가 설명했던 그 방법이다.
행렬의 크기가 주어진 뒤, 바로 행렬의 값이 주어지기 때문에 패딩 과정을 따로 거치기 보다는 행렬의 크기 최댓값이 100이므로 2n과 가장 가까운 128로 미리 선언해주고 채워주도록 한다.
코드를 보면 이해가 갈 것이다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
// 행렬 A
int[][] A = new int[128][128];
for (int i = 0; i < N; i++) {
st = new StringTokenizer(br.readLine(), " ");
for (int j = 0; j < M; j++) {
A[i][j] = Integer.parseInt(st.nextToken());
}
}
st = new StringTokenizer(br.readLine(), " ");
M = Integer.parseInt(st.nextToken());
int K = Integer.parseInt(st.nextToken());
// 행렬 B 입력
int[][] B = new int[128][128];
for (int i = 0; i < M; i++) {
st = new StringTokenizer(br.readLine(), " ");
for (int j = 0; j < K; j++) {
B[i][j] = Integer.parseInt(st.nextToken());
}
}
/*
* 2^n꼴의 정사각 행렬로 패딩해야 하기 때문에 패딩 된 사이즈를 구해야한다.
* 즉, N과 K, M중 가장 큰 값을 기준으로 해당 값보다 크면서
* 2^n에 가장 가까운 값을 얻어야 한다.
*/
int big = Math.max(Math.max(N, K), M);
int size = 1;
while(true) {
if(size >= big) {
break;
}
size *= 2;
}
// 분할정복 메소드 호출
int[][] C = multiply(A, B, size);
StringBuilder sb = new StringBuilder();
// 출력
for (int i = 0; i < N; i++) {
for (int j = 0; j < K; j++) {
sb.append(C[i][j] + " ");
}
sb.append('\n');
}
System.out.println(sb);
}
public static int[][] multiply(int[][] A, int[][] B, int size) {
int[][] C = new int[size][size]; // 완성시킬 C 배열
// size가 1로 가장 작게 쪼개질 경우 (0,0) 원소밖에 없으므로 해당 원소의 곱을 반환
if (size == 1) {
C[0][0] = A[0][0] * B[0][0];
return C;
}
int newSize = size / 2; // 부분행렬에 대한 사이즈
// A의 부분행렬
int[][] a11 = subArray(A, 0, 0, newSize);
int[][] a12 = subArray(A, 0, newSize, newSize);
int[][] a21 = subArray(A, newSize, 0, newSize);
int[][] a22 = subArray(A,newSize, newSize, newSize);
// A의 부분행렬
int[][] b11 = subArray(B, 0, 0, newSize);
int[][] b12 = subArray(B, 0, newSize, newSize);
int[][] b21 = subArray(B, newSize, 0, newSize);
int[][] b22 = subArray(B, newSize, newSize, newSize);
// M1 := (A11 + A22) * (B11 + B22)
int[][] M1 = multiply(add(a11, a22, newSize), add(b11, b22, newSize), newSize);
// M2 := (A21 + A22) * B11
int[][] M2 = multiply(add(a21, a22, newSize), b11, newSize);
// M3 := A11 * (B12 - B22)
int[][] M3 = multiply(a11, sub(b12, b22, newSize), newSize);
// M4 := A22 * (B21 − B11)
int[][] M4 = multiply(a22, sub(b21, b11, newSize), newSize);
// M5 := (A11 + A12) * B22
int[][] M5 = multiply(add(a11, a12, newSize), b22, newSize);
// M6 := (A21 - A11) * (B11 + B12)
int[][] M6 = multiply(sub(a21, a11, newSize), add(b11, b12, newSize), newSize);
// M7 := (A12 - A22) * (B21−B22)
int[][] M7 = multiply(sub(a12, a22, newSize), add(b21, b22, newSize), newSize);
// C11 := M1 + M4 − M5 + M7
int[][] c11 = add(sub(add(M1, M4, newSize), M5, newSize), M7, newSize);
// C12 := M3 + M5
int[][] c12 = add(M3, M5, newSize);
// C21 := M2 + M4
int[][] c21 = add(M2, M4, newSize);
// C22 := M1 − M2 + M3 + M6
int[][] c22 = add(add(sub(M1, M2, newSize), M3, newSize), M6, newSize);
// 구해진 C의 부분행렬들 합치기
merge(c11, C, 0, 0, newSize);
merge(c12, C, 0, newSize, newSize);
merge(c21, C, newSize, 0, newSize);
merge(c22, C, newSize, newSize, newSize);
return C;
}
// 행렬 뺄셈
public static int[][] sub(int[][] A, int[][] B, int size) {
int[][] C = new int[size][size];
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
C[i][j] = A[i][j] - B[i][j];
}
}
return C;
}
// 행렬 덧셈
public static int[][] add(int[][] A, int[][] B, int size) {
int n = size;
int[][] C = new int[n][n];
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
C[i][j] = A[i][j] + B[i][j];
}
}
return C;
}
// 부분행렬을 반환하는 메소드
public static int[][] subArray(int[][] src, int row, int col, int size) {
int[][] dest = new int[size][size];
for (int dset_i = 0, src_i = row; dset_i < size; dset_i++, src_i++) {
for (int dest_j = 0, src_j = col; dest_j < size; dest_j++, src_j++) {
dest[dset_i][dest_j] = src[src_i][src_j];
}
}
return dest;
}
// src는 복사할 배열(=부분배열), dest는 합쳐질 배열(= 배열 C)
public static void merge(int[][] src, int[][] dest, int row, int col, int size) {
for (int src_i = 0, dest_i = row; src_i < size; src_i++, dest_i++) {
for (int src_j = 0, dest_j = col; src_j < size; src_j++, dest_j++) {
dest[dest_i][dest_j] = src[src_i][src_j];
}
}
}
}
필자가 설명했던 코드 그대로 갖고왔다.
- 방법 3 : [개선 된 스트라센 방법]
방법2로 제출해보시면 알겠지만, 행렬의 덧셈과 뺼셈, 각 재귀 단계에서 생성되는 부분배열이 많다.
이는 행렬의 크기가 작을수록 상대적으로 시간복잡도에 비해 오버헤드가 커진다는 의미다. 그래서 실제로도 단순하게 반복문으로 많이 풀이하기도 한다.
만약 행렬의 크기가 매우 클 경우에는 스트라센 방법이 시간이 덜 걸리긴 할테지만, 위 문제에서 주어지는 최댓값인 100은 컴퓨터 입장에서는 그렇게 큰 값이 아니다.
그럼 어떻게 해야할까?
임계값(threshold)을 정해서 일정 크기 이하가 되면 반복문으로 행렬 곱을 하도록 처리하는 것이다. 쉽게 말해 1번 방법과 2번 방법을 짬뽕시키는 것이다.
많은 논문들을 보니 대략 70 언저리쯤으로 잡는 것 같아 보였다.
필자는 16정도로 잡아보도록 하겠다.
코드를 보면 이해가 갈 것이다.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
public class Main {
private static final int threshold = 16; // 임계값
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine(), " ");
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
// 행렬 A
int[][] A = new int[128][128];
for (int i = 0; i < N; i++) {
st = new StringTokenizer(br.readLine(), " ");
for (int j = 0; j < M; j++) {
A[i][j] = Integer.parseInt(st.nextToken());
}
}
st = new StringTokenizer(br.readLine(), " ");
M = Integer.parseInt(st.nextToken());
int K = Integer.parseInt(st.nextToken());
// 행렬 B 입력
int[][] B = new int[128][128];
for (int i = 0; i < M; i++) {
st = new StringTokenizer(br.readLine(), " ");
for (int j = 0; j < K; j++) {
B[i][j] = Integer.parseInt(st.nextToken());
}
}
/*
* 2^n꼴의 정사각 행렬로 패딩해야 하기 때문에 패딩 된 사이즈를 구해야한다.
* 즉, N과 K, M중 가장 큰 값을 기준으로 해당 값보다 크면서
* 2^n에 가장 가까운 값을 얻어야 한다.
*/
int big = Math.max(Math.max(N, K), M);
int size = 1;
while(true) {
if(size >= big) {
break;
}
size *= 2;
}
// 분할정복 메소드 호출
int[][] C = multiply(A, B, size);
StringBuilder sb = new StringBuilder();
// 출력
for (int i = 0; i < N; i++) {
for (int j = 0; j < K; j++) {
sb.append(C[i][j] + " ");
}
sb.append('\n');
}
System.out.println(sb);
}
// 추가 된 행렬 loop 곱 메소드
public static int[][] loopMultiply(int[][] A, int[][] B, int size) {
int res[][] = new int[size][size];
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
for (int k = 0; k < size; k++) {
res[i][j] += A[i][k] * B[k][j];
}
}
}
return res;
}
public static int[][] multiply(int[][] A, int[][] B, int size) {
int[][] C = new int[size][size]; // 완성시킬 C 배열
if (size <= threshold) { // 임계값 이하가 되면 loop로 곱셈을 하여 반환한다.
return C = loopMultiply(A, B, size);
}
int newSize = size / 2; // 부분행렬에 대한 사이즈
// A의 부분행렬
int[][] a11 = subArray(A, 0, 0, newSize);
int[][] a12 = subArray(A, 0, newSize, newSize);
int[][] a21 = subArray(A, newSize, 0, newSize);
int[][] a22 = subArray(A,newSize, newSize, newSize);
// A의 부분행렬
int[][] b11 = subArray(B, 0, 0, newSize);
int[][] b12 = subArray(B, 0, newSize, newSize);
int[][] b21 = subArray(B, newSize, 0, newSize);
int[][] b22 = subArray(B, newSize, newSize, newSize);
// M1 := (A11 + A22) * (B11 + B22)
int[][] M1 = multiply(add(a11, a22, newSize), add(b11, b22, newSize), newSize);
// M2 := (A21 + A22) * B11
int[][] M2 = multiply(add(a21, a22, newSize), b11, newSize);
// M3 := A11 * (B12 - B22)
int[][] M3 = multiply(a11, sub(b12, b22, newSize), newSize);
// M4 := A22 * (B21 − B11)
int[][] M4 = multiply(a22, sub(b21, b11, newSize), newSize);
// M5 := (A11 + A12) * B22
int[][] M5 = multiply(add(a11, a12, newSize), b22, newSize);
// M6 := (A21 - A11) * (B11 + B12)
int[][] M6 = multiply(sub(a21, a11, newSize), add(b11, b12, newSize), newSize);
// M7 := (A12 - A22) * (B21−B22)
int[][] M7 = multiply(sub(a12, a22, newSize), add(b21, b22, newSize), newSize);
// C11 := M1 + M4 − M5 + M7
int[][] c11 = add(sub(add(M1, M4, newSize), M5, newSize), M7, newSize);
// C12 := M3 + M5
int[][] c12 = add(M3, M5, newSize);
// C21 := M2 + M4
int[][] c21 = add(M2, M4, newSize);
// C22 := M1 − M2 + M3 + M6
int[][] c22 = add(add(sub(M1, M2, newSize), M3, newSize), M6, newSize);
// 구해진 C의 부분행렬들 합치기
merge(c11, C, 0, 0, newSize);
merge(c12, C, 0, newSize, newSize);
merge(c21, C, newSize, 0, newSize);
merge(c22, C, newSize, newSize, newSize);
return C;
}
// 행렬 뺄셈
public static int[][] sub(int[][] A, int[][] B, int size) {
int[][] C = new int[size][size];
for (int i = 0; i < size; i++) {
for (int j = 0; j < size; j++) {
C[i][j] = A[i][j] - B[i][j];
}
}
return C;
}
// 행렬 덧셈
public static int[][] add(int[][] A, int[][] B, int size) {
int n = size;
int[][] C = new int[n][n];
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
C[i][j] = A[i][j] + B[i][j];
}
}
return C;
}
// 부분행렬을 반환하는 메소드
public static int[][] subArray(int[][] src, int row, int col, int size) {
int[][] dest = new int[size][size];
for (int dset_i = 0, src_i = row; dset_i < size; dset_i++, src_i++) {
for (int dest_j = 0, src_j = col; dest_j < size; dest_j++, src_j++) {
dest[dset_i][dest_j] = src[src_i][src_j];
}
}
return dest;
}
// src는 복사할 배열(=부분배열), dest는 합쳐질 배열(= 배열 C)
public static void merge(int[][] src, int[][] dest, int row, int col, int size) {
for (int src_i = 0, dest_i = row; src_i < size; src_i++, dest_i++) {
for (int src_j = 0, dest_j = col; src_j < size; src_j++, dest_j++) {
dest[dest_i][dest_j] = src[src_i][src_j];
}
}
}
}
한 번 기회가 된다면 100 이상의 매우 큰 수의 행렬을 사용하여 한 번 어느 시점부터 스트라센 방법이 더 효율적인지 테스트 해보셔도 좋을 것 같다.
- 성능

채점 번호 : 29002941 - 방법 3 : 개선 된 스트라센
채점 번호 : 29002935 - 방법 2 : 스트라센
채점 번호 : 29002929 - 방법 1 : 반복문
결과에서 보이듯 작은 행렬 단위에서는 반복문 처리가 훨씬 빠르다.
반면에 행렬의 크기가 1이 될 때 까지 쪼개는 방식의 경우 오버헤드가 너무 커져 메모리와 시간을 많이 잡아먹는 것을 볼 수 있다.
그렇기에 방법 1과 2를 잘 섞어서 최적의 조건을 찾아내는 것도 중요하다는 것을 보여주고 싶었다.
- 정리
이 번 문제 자체는 어려운 점이 없었을 것이다. 다만, 분할정복 파트인 만큼 분할정복으로, 정확하게는 스트라센 알고리즘을 어떻게 분할정복으로 풀이해야하는지에 대한 접근 방식으로도 같이 풀이해보았다.
사실 코드가 길고 어려워보이지만, 수식만 조금 들여다보면 그리 어려운 것은 아니니 한 번 쯤은 제대로 짚고 넘어가면 좋을 법한 문제인 것 같다.
만약 어렵거나 이해가 되지 않은 부분이 있다면 언제든 댓글 남겨주시면 최대한 빠르게 답변드리겠다.
'JAVA - 백준 [BAEK JOON] > 분할 정복' 카테고리의 다른 글
| [백준] 11444번 : 피보나치 수 6 - JAVA [자바] (12) | 2021.05.27 |
|---|---|
| [백준] 10830번 : 행렬 제곱 - JAVA [자바] (8) | 2021.05.24 |
| [백준] 11401번 : 이항 계수 3 - JAVA [자바] (2) | 2021.04.23 |
| [백준] 1629번 : 곱셈 - JAVA [자바] (21) | 2021.04.07 |
| [백준] 1780번 : 종이의 개수 - JAVA [자바] (4) | 2021.04.05 |