[백준] 1932번 : 정수 삼각형 - JAVA [자바]
1932번: 정수 삼각형
문제 7 3 8 8 1 0 2 7 4 4 4 5 2 6 5 위 그림은 크기가 5인 정수 삼각형의 한 모습이다. 맨 위층 7부터 시작해서 아래에 있는 수 중 하나를 선택하여 아래층으로 내려올 때, 이제까지 선택된 수의 합이 최�
www.acmicpc.net
-
문제
조금만 살펴보면 쉽게 풀 수 있는 문제다. 다만 가끔 위에서 아래로 내려오면서 최댓값 경로만 찾아서 하는 경우가 있는데 그렇게 하면 100% 오답이 난다. 또한 DP에 한 번 탐색한 값을 재활용(Memoization)하지 않고 불필요하게 재귀호출을 다 해주면 시간초과가 나니 이 점 유의하도록 하자.
- 알고리즘 [접근 방법]
정답률이 높은 것을 보아 아마 다들 쉽게 풀 수 있던 것 같다. 마침 삼각형으로 주어지니 그림으로 천천히 살펴보도록 하자.
먼저 삼각형을 입력받을 2차원 배열 arr와 경로 합을 갖을 DP배열, 이렇게 두 개가 있어야한다. 그리고 삼각형의 밑변, 즉 마지막 값은 DP배열에도 똑같이 저장해준다. 그림으로 보면 아래와 같다.

그리고 'DP를 위에서부터 탐색'하는 것이다.
맨 위에서 탐색해보자. 이 때 아래의 양쪽 값 중 최댓값을 찾아야 한다. 하지만, 위 그림에서 보듯이 위에서 두 번째 줄의 값 또한 비어있다. 그럼 재귀호출을 통해 다시 그 아래의 양쪽 값 중 최댓값을 찾는다.
이런식으로 반복하다보면 양쪽에 값이 있는 경우를 만나게 된다. 그럼 양쪽의 값 중 최댓값과 현재 위치의 배열 값을 더하여 DP에 저장해주면 된다. 간단하게 코드로 보자면 이렇다.
// depth는 깊이(행), idx는 인덱스(열)를 의미
int find(int depth, int idx) {
// 만약 맨 밑(깊이)의 행에 도달하면 해당 인덱스를 반환한다.
if(depth == N - 1) return dp[depth][idx];
// 만약 아직 탐색하지 않은 위치라면 다음 행의 양쪽 열 중 최댓값을 구함
if (dp[depth][idx] == null) {
/*
바로 다음행의 인덱스와 그 오른쪽의 인덱스 중
큰 값 찾아 dp에 현재 인덱스의 값과 더하여 저장
*/
dp[depth][idx] = max(find(depth + 1, idx), find(depth + 1, idx + 1)) + arr[depth][idx];
}
return dp[depth][idx];
}
위 알고리즘처럼 만약 왼쪽부터 탐색(재귀호출)한다고 가정한다면 가장 먼저 DP에 채워지는 곳은 아래와 같을 것이다.

위 그림처럼 각 밑의 값 중 최댓값과 현 위치의 값을 더해나가면서 가는 방식이다. 그리고 DP[0][0]에 최종적으로 쌓인 누적 합이 최댓값이 될 것이다.
- 2가지 방법을 사용하여 풀이한다.
여느 때와 다름없이 입력 방법에서 Scanner와 BufferedReader 방식의 성능 비교를 해 볼 것이다.
1 . Scanner
2. BufferedReader
- 풀이
- 방법 1 : Scanner
import java.util.Scanner;
public class Main {
static int[][] arr;
static Integer[][] dp;
static int N;
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
N = in.nextInt();
arr = new int[N][N];
dp = new Integer[N][N];
// 배열 초기화
for (int i = 0; i < N; i++) {
for (int j = 0; j < i + 1; j++) {
arr[i][j] = in.nextInt();
}
}
// 가장 마지막 행의 값들을 DP의 마지막 행에도 똑같이 복사
for (int i = 0; i < N; i++) {
dp[N - 1][i] = arr[N - 1][i];
}
System.out.println(find(0, 0));
}
static int find(int depth, int idx) {
// 마지막 행일 경우 현재 위치의 dp값 반환
if(depth == N - 1) return dp[depth][idx];
// 탐색하지 않았던 값일 경우 다음 행의 양쪽 값 비교
if (dp[depth][idx] == null) {
dp[depth][idx] = Math.max(find(depth + 1, idx), find(depth + 1, idx + 1)) + arr[depth][idx];
}
return dp[depth][idx];
}
}
가장 기본적인 방법이라 할 수 있겠다.
단 주의할 것은 필자의 경우 대개 DP를 쓸 때 Integer라는 객체를 통해 객체배열로 활용한다. 이유는 int[] 배열로 쓰면 0이라는 값이 default(디폴트)로 초기화가 되어있는데 문제에서 주어진 값의 범위가 0~9999으로 0이 겹치게 된다. 물론 탐색 전에 -1같은 입력 범위 밖의 수들로 초기화 해주어도 되지만 그런 것보단 객체배열의 default값인 null을 활용하는게 좀 더 편하다.
다만, 메모리가 초과될 수 있으니 이 점 유의하길 바란다. 기본적으로 Integer[] 배열은 int[] 배열의 4배정도의 메모리가 소모된다고 하니 자칫 재귀가 매우 깊어지거나 입력 값이 많은 경우에는 객체배열을 피하는게 좋다.
- 방법 2 : BufferedReader
입력 방법을 Scanner 대신 BufferedReader 을 사용하여 풀이하는 방법이다. 단, BufferedReader 는 문자열을 한 줄로 읽기 때문에 N과 M을 구분하기 위해 공백을 기준으로 문자열을 분리해주어야하니 StringTokenizer 을 사용하여 풀도록 하겠다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.util.StringTokenizer;
public class Main {
static int[][] arr;
static Integer[][] dp;
static int N;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
N = Integer.parseInt(br.readLine());
arr = new int[N][N];
dp = new Integer[N][N];
StringTokenizer st;
for (int i = 0; i < N; i++) {
st = new StringTokenizer(br.readLine(), " ");
for (int j = 0; j < i + 1; j++) {
arr[i][j] = Integer.parseInt(st.nextToken());
}
}
for (int i = 0; i < N; i++) {
dp[N - 1][i] = arr[N - 1][i];
}
System.out.println(find(0, 0));
}
static int find(int depth, int idx) {
// 마지막 행일 경우 현재 위치의 dp값 반환
if(depth == N - 1) return dp[depth][idx];
// 탐색하지 않았던 값일 경우 다음 행의 양쪽 값 비교
if (dp[depth][idx] == null) {
dp[depth][idx] = Math.max(find(depth + 1, idx), find(depth + 1, idx + 1)) + arr[depth][idx];
}
return dp[depth][idx];
}
}
크게 어려울 것은 없을 것이다.
- 성능

채점 번호 : 22022255 - 방법 2 : BufferedReader
채점 번호 : 22022250 - 방법 1 : Scanner
입력의 경우 확실히 Scanner 보다는 BufferedReader 가 빠른 걸 볼 수 있다.
- 정리
필자가 보통 포스팅하기 전에 어느 부분에서 사람들이 많이 틀리는지 질문게시판을 보는데, 재귀호출부분에서 탐색했던 곳을 반복해서 탐색하는 분들이 좀 계신 것 같았다. 물론 이전 문제들에서 그렇게 해서 풀렸을지는 몰라도 좋은 방법은 아니다. DP를 통해 이미 탐색했던 노드의 값을 저장하는 것, 즉 Memoization 이 매우 중요하다. 불필요한 연산을 줄여줌으로 성능개선을 할 수 있다.
실제로 이미 탐색한 데이터를 재활용 여부에 따라 시간차이는 엄청 많이 차이난다. 필자가 위 두 문제를 바탕으로 N의 값을 달리하여 재귀호출을 했을 때 재활용(Memoization)을 하냐 안하냐를 테스트를 했는데 결과를 엄청 차이가 났다.
먼저 우리가 평소 했던 것 처럼 이미 탐색한 노드를 재활용하는 방식은 N의 값에 따라 다음과 같은 시간(초)가 걸렸다.

N이 13000값이여도 1분이 채 안걸린다. (물론 컴퓨터마다 성능차이에 의해 조금씩 차이는 있을 수 있다.)
그러면 Memoization을 안하면 어떻게 되는지 보자.
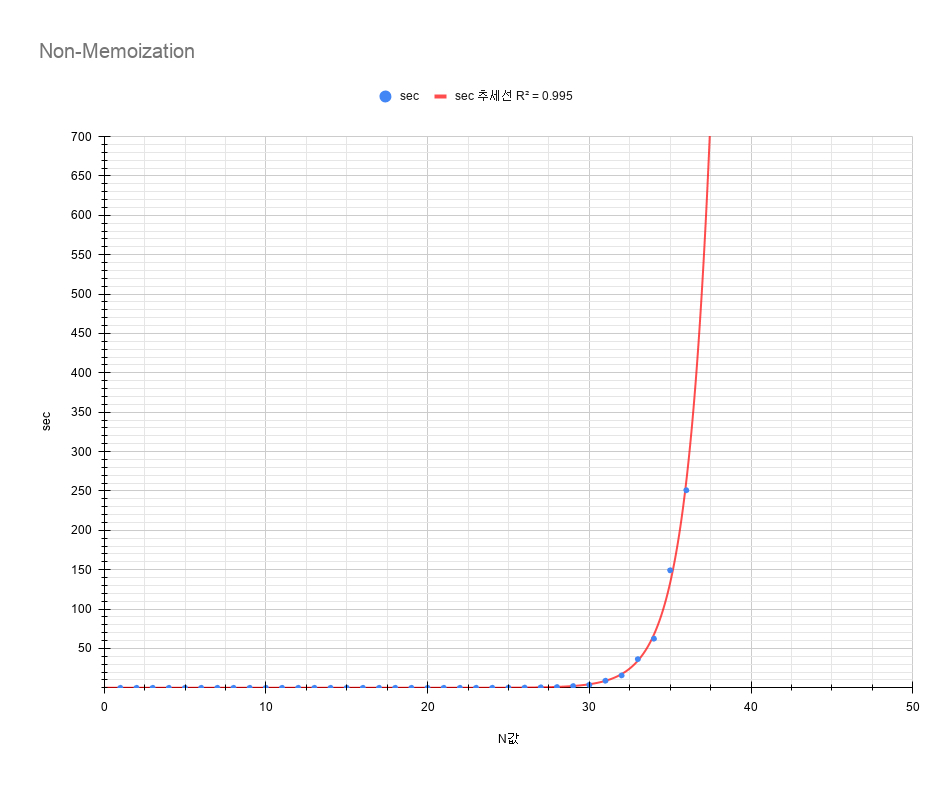
보면 알 수 있듯이 효율이 엄청나게 떨어진다. N=35만 되더라도 4분이 넘게 걸리는 걸 볼 수 있다. 좀 더 자세히 보기 위해 두 차트를 하나로 묶어 비교하자면 이렇다.
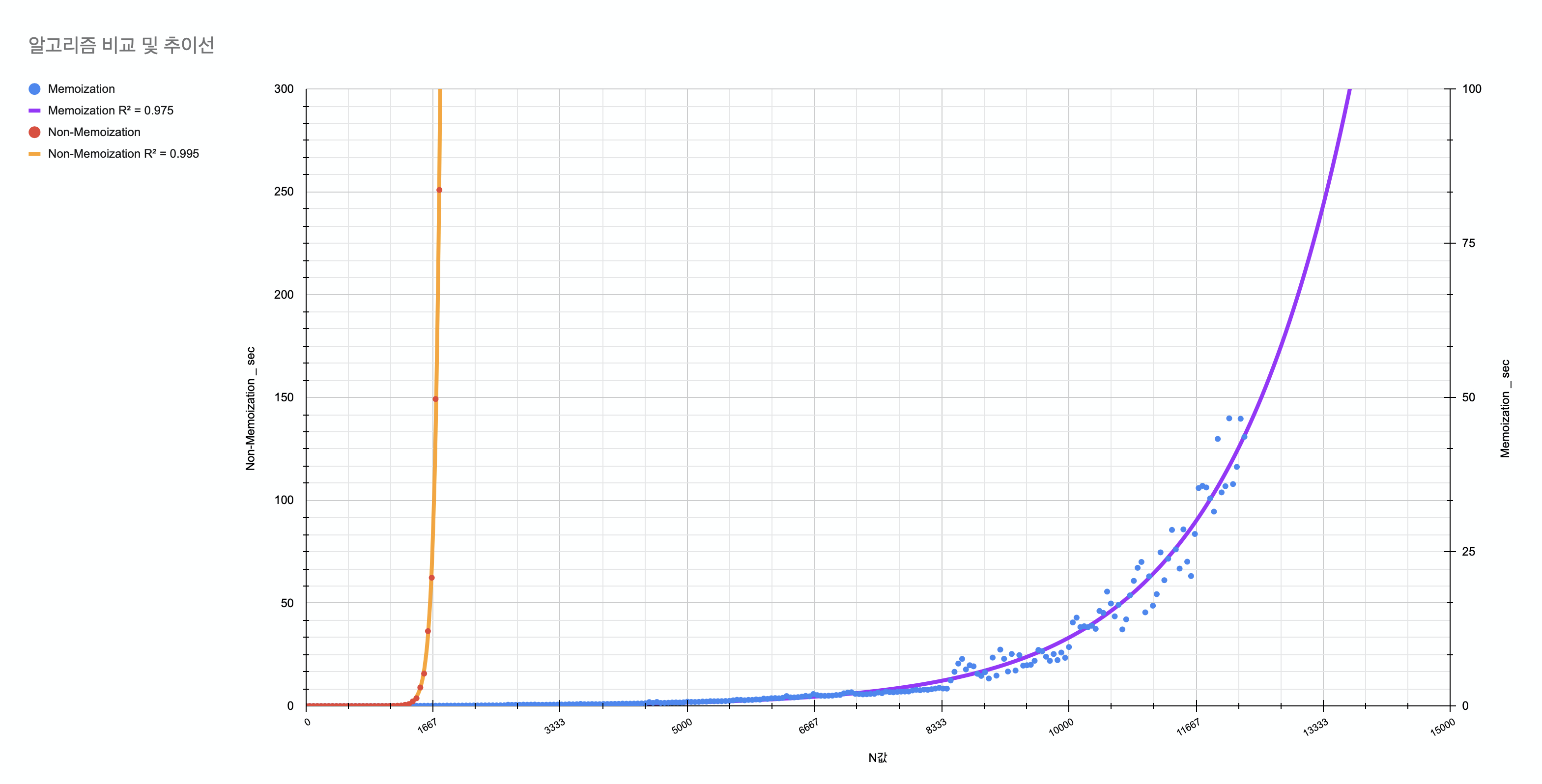
주황색 선이 방문했던 노드를 재활용하지 않을 경우의 추이선, 파란색이 방문했던 노드 값을 재활용하는 경우의 추이선이다. 실제로 왼쪽 세로축과 오른쪽 세로축의 데이터 범위가 3배 차이나니 위 그림보다 실로 더 차이가 나는 것이다.
특히 재귀호출이 깊어지면 깊어질수록, 탐색량이 많아질수록 더욱 가치가 올라가니 잘 익혀두면서 어떻게 해야 효율적인 코드를 짤 수 있는지 고민해보시길 바란다. 만약 어렵거나 이해가 되지 않은 부분이 있다면 언제든 댓글 남겨주시면 최대한 빠르게 답변드리겠다.
'JAVA - 백준 [BAEK JOON] > 동적 계획법 1' 카테고리의 다른 글
| [백준] 1463번 : 1로 만들기 - JAVA [자바] (36) | 2020.08.28 |
|---|---|
| [백준] 2579번 : 계단 오르기 - JAVA [자바] (35) | 2020.08.27 |
| [백준] 1149번 : RGB거리 - JAVA[자바] (18) | 2020.08.11 |
| [백준] 9461번 : 파도반 수열 - JAVA [자바] (11) | 2020.08.05 |
| [백준] 1904번 : 01타일 - JAVA [자바] (29) | 2020.07.24 |