자바 [JAVA] - Singly LinkedList (단일 연결리스트) 구현하기
자료구조 관련 목록 링크 펼치기
0. 자바 컬렉션 프레임워크 (Java Collections Framework)
3. 단일 연결리스트 (Singly LinkedList) - [현재 페이지]
4. 이중 연결리스트 (Doubly LinkedList)
6. 스택 (Stack)
11. 연결리스트 덱 (LinkedList Deque)
12. 힙 (Heap)
15. 해시 셋 (Hash Set)
17. 이진 탐색 트리 (Binary Search Tree)
- Singly LinkedList
만약 이 글을 처음 접한다면 자바 컬렉션 프레임워크 (Java Collections Framework) 글과 리스트 인터페이스 (List Interface)을 먼저 보고 오셨으면 한다.
이 번에 구현해볼 것은 LinkedList의 한 종류인 Singly LinkedList를 구현해보고자 한다.
LinkedLIst의 경우 ArrayList와 가장 큰 차이점이라 한다면 바로 '노드'라는 객체를 이용하여 연결한다는 것이다. ArrayList의 경우 최상위 타입인 오브젝트 배열(Object[])을 사용하여 데이터를 담아두었다면, LinkedList 는 배열을 이용하는 것이 아닌 하나의 객체를 두고 그 안에 데이터와 다른 노드를 가리키는 레퍼런스 데이터로 구성하여 여러 노드를 하나의 체인(chain)처럼 연결하는 것이다.
글만으로는 이해하기 어려울 수 있으니 차근차근 짚어보도록 하자.
앞서 데이터와 다른 노드를 가리킬 주소데이터를 담을 객체가 필요하다고 했다. 그리고 우리는 이 것을 '노드(node)'라고 부른다. node가 가장 기초적 단위라고 보면 되겠다.
즉, 노드 하나의 구조를 보자면 이렇다.

그리고 위 구조에서 사용자가 저장할 데이터는 data 변수에 담기고, reference 데이터(참조 데이터)는 다음에 연결할 노드를 가리키는 데이터가 담긴다.
위와같은 노드들이 여러개가 연결 되어있는 것을 연결 리스트, 즉 LinkedList라고 한다.
조금 더 쉽게 배열과 LinkedList 를 그림으로 비교해보자.
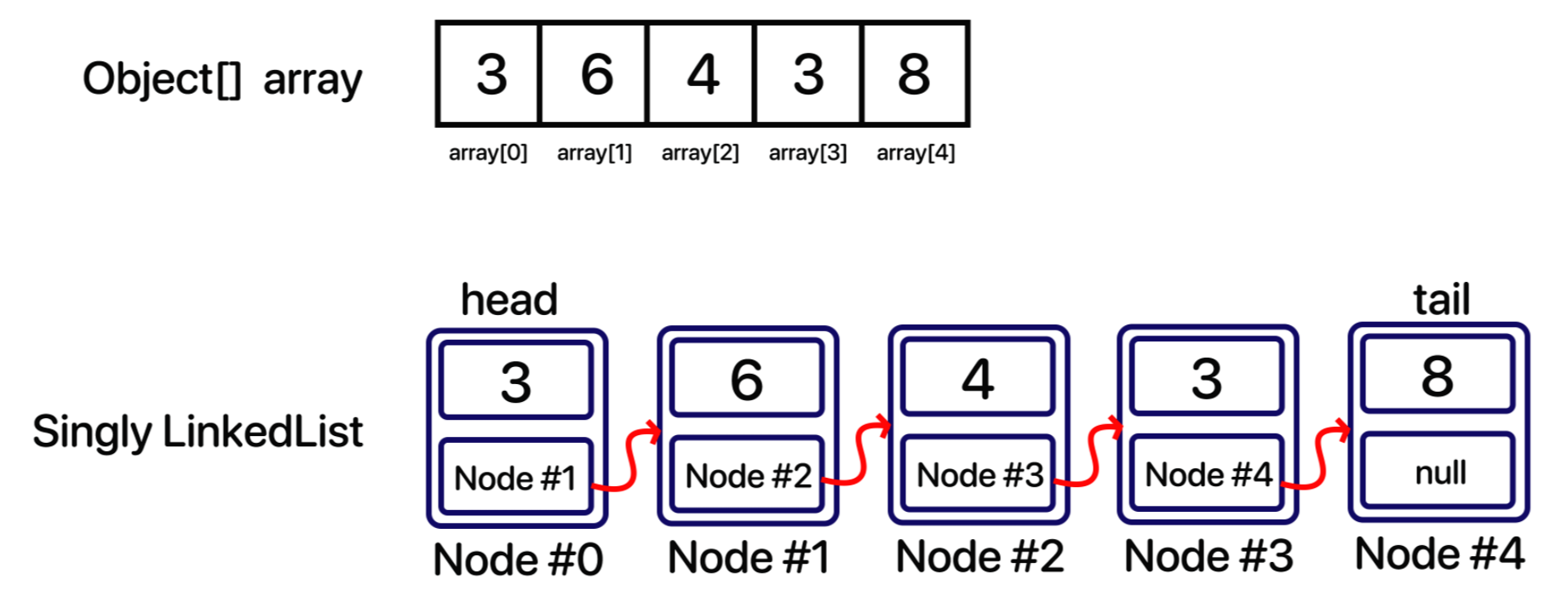
위 그림에서 보면 알겠지만 각각의 래퍼런스 변수는 다음 노드객체를 가리키고 있다. 이렇게 단방향으로 연결 된 리스트를 LinkedList 중에서도 Singly LinkedList라고 하는 것이다.
한 마디로 정리하자면 노드들을 연결시킨 형태가 바로 LinkedList 다.
이렇게 연결된 노드들에서 '삽입'을 한다면 링크만 바꿔주면 되기 때문에 매우 편리하며, 반대로 '삭제'를 한다면 삭제 할 노드에 연결 된 이전노드에서 링크를 끊고 삭제할 노드의 다음 노드를 연결해주면 된다.
처음 접한다면 아직 잘 이해가 안 갈 수도 있다. 천천히 구현해보면서 알아보도록 하자.
- Node 구현
그러면 우리가 LinkedList를 구현하기에 앞서 가장 기본적인 데이터를 담을 Node 클래스를 먼저 구현해주어야 한다. 노드 클래스는 앞으로 구현 할 LinkedList와 같은 패키지(package)에서 생성 할 것이다.
[Node.java]
class Node<E> {
E data;
Node<E> next; // 다음 노드객체를 가리키는 래퍼런스 변수
Node(E data) {
this.data = data;
this.next = null;
}
}
next 가 앞서 그림에서 보여주었던 Reference 변수다. 다음 노드를 가리키는 변수이며, '노드 자체'를 가리키기 때문에 타입 또한 Node<E>타입으로 지정해주어야 한다.
그리고 위 노드를 이용하기 위한 단일 연결리스트(Singly LinkedList)를 구현하면 된다.
- Singly LinkedList 구현
- 사전 준비
[List Interface 소스]
[List.java]
package Interface_form;
/**
*
* 자바 List Interface입니다. <br>
* List는 ArrayList, SinglyLinkedList, DoublyLinked에 의해 각각 구현됩니다.
*
* @author st_lab
* @param <E> the type of elements in this list
*
* @version 1.0
*
*/
public interface List<E> {
/**
* 리스트에 요소를 추가합니다.
*
* @param value 리스트에 추가할 요소
* @return 리스트에서 중복을 허용하지 않을 경우에 리스트에 이미 중복되는
* 요소가 있을 경우 {@code false}를 반환하고, 중복되는 원소가
* 없을경우 {@code true}를 반환
*/
boolean add(E value);
/**
* 리스트에 요소를 특정 위치에 추가합니다.
* 특정 위치 및 이후의 요소들은 한 칸씩 뒤로 밀립니다.
*
* @param index 리스트에 요소를 추가할 특정 위치 변수
* @param value 리스트에 추가할 요소
*/
void add(int index, E value);
/**
* 리스트의 index 위치에 있는 요소를 삭제합니다.
*
* @param index 리스트에서 삭제 할 위치 변수
* @return 삭제된 요소를 반환
*/
E remove(int index);
/**
* 리스트에서 특정 요소를 삭제합니다. 동일한 요소가
* 여러 개일 경우 가장 처음 발견한 요소만 삭제됩니다.
*
* @param value 리스트에서 삭제할 요소
* @return 리스트에 삭제할 요소가 없거나 삭제에 실패할
* 경우 {@code false}를 반환하고 삭제에 성공할 경우 {@code true}를 반환
*/
boolean remove(Object value);
/**
* 리스트에 있는 특정 위치의 요소를 반환합니다.
*
* @param index 리스트에 접근할 위치 변수
* @return 리스트의 index 위치에 있는 요소 반환
*/
E get(int index);
/**
* 리스트에서 특정 위치에 있는 요소를 새 요소로 대체합니다.
*
* @param index 리스트에 접근할 위치 변수
* @param value 새로 대체할 요소 변수
*/
void set(int index, E value);
/**
* 리스트에 특정 요소가 리스트에 있는지 여부를 확인합니다.
*
* @param value 리스트에서 찾을 특정 요소 변수
* @return 리스트에 특정 요소가 존재할 경우 {@code true}, 존재하지 않을 경우 {@code false}를 반환
*/
boolean contains(Object value);
/**
* 리스트에 특정 요소가 몇 번째 위치에 있는지를 반환합니다.
*
* @param value 리스트에서 위치를 찾을 요소 변수
* @return 리스트에서 처음으로 요소와 일치하는 위치를 반환.
* 만약 일치하는 요소가 없을경우 -1 을 반환
*/
int indexOf(Object value);
/**
* 리스트에 있는 요소의 개수를 반환합니다.
*
* @return 리스트에 있는 요소 개수를 반환
*/
int size();
/**
* 리스트에 요소가 비어있는지를 반환합니다.
* @return 리스트에 요소가 없을경우 {@code true}, 요소가 있을경우 {@code false}를 반환
*/
boolean isEmpty();
/**
* 리스트에 있는 요소를 모두 삭제합니다.
*/
public void clear();
}
[Node class 소스] - 앞서 구현함
[구현 바로가기]
<필수 목록>
◦ get, set, indexOf, contains 메소드 구현
<부가 목록>
◦ 전체 코드
[Singly LinkedList 클래스 및 생성자 구성하기]
Singly LinkedLIst 이름은 너무 기니 SLinkedList로 이름을 대체하겠다.
일단 사전에 만들어두었던 List 인터페이스를 implements 해준다.(필자는 Interface_form 이라는 패키지에 만들었기 때문에 import Interface_form.List;를 해준다.)
implements 를 하면 class 옆에 경고표시가 뜰 텐데 List 인터페이스에 있는 메소드들을 구현하라는 것이다. 어차피 모두 구현해나갈 것이기 때문에 일단은 무시한다.
[SLinkedList.java]
import Interface_form.List;
public class SLinkedList<E> implements List<E> {
private Node<E> head; // 노드의 첫 부분
private Node<E> tail; // 노드의 마지막 부분
private int size; // 요소 개수
// 생성자
public SLinkedList() {
this.head = null;
this.tail = null;
this.size = 0;
}
}
변수부터 먼저 차례대로 설명해주도록 하겠다.
Node<E> head : 리스트의 가장 첫 노드를 가리키는 변수다.
Node<E> tail : 리스트의 가장 마지막 노드를 가리키는 변수다.
size : 리스트에 있는 요소의 개수(=연결 된 노드의 개수)
처음 단일 연결리스트를 생성 할 때에는 아무런 데이터가 없으므로 당연히 head와 tail이 가리킬 노드가 없기에 null로 초기화 및 size는 0으로 초기화 해주도록 한다.
메인 클래스에서 객체생성 한다고 한다면 다음과 같다.
[Main.java]
SLinkedList<Integer> list = new SLinkedList<>();
[search 메소드 구현]
본격적으로 SLinkedList 구현에 앞서 search()메소드를 작성하려 한다. 이유는 단일 연결리스트이다보니 특정 위치의 데이터를 삽입, 삭제, 검색하기 위해서는 처음 노드(head)부터 next변수를 통해 특정 위치까지 찾아가야 하기 때문이다.
이를 위해 미리 search()메소드를 구현해놓고 쓰면 매우 편리하다. 그리 어렵지 않은 메소드이니 미리 구현해놓도록 하자.
// 특정 위치의 노드를 반환하는 메소드
private Node<E> search(int index) {
// 범위 밖(잘못된 위치)일 경우 예외 던지기
if(index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
Node<E> x = head; // head가 기리키는 노드부터 시작
for (int i = 0; i < index; i++) {
x = x.next; // x노드의 다음 노드를 x에 저장한다
}
return x;
}
[add 메소드 구현]
이제 본격적으로 SLinkedList에 데이터를 추가할 수 있도록 해보자. 리스트 인터페이스에 있는 add() 메소드를 반드시 구현해야하는 것이기 때문에 Override(재정의)를 한다고 보면 된다.
add 메소드에는 ArrayList와 마찬가지로 크게 3가지로 분류가 된다.
- 가장 앞부분에 추가 - addFirst(E value)
- 가장 마지막 부분에 추가 (기본값) - addLast(E value)
- 특정 위치에 추가 - add(int index, E value)
자바에 내장되어있는 LinkedList에서는 add() 역할을 addLast() 메소드가 하고, 특정 위치에 추가는 add(int index, E element) 메소드, 가장 첫 부분에 추가는 addFisrt()가 한다.
1. addFisrt(E value)
먼저 기본 값인 add()및 addLast()를 구현하기 전에 먼저 addFisrt()를 구현하고자 한다.
이유는 addLast를 구현 할 때 알 수 있으니 일단은 가장 앞에 추가하는 것 부터 하자.
앞서 언급했듯이 연결리스트는 말 그대로 '링크'로 연결 된 리스트다. 즉, 가장 앞에 추가한다면 다음과 같은 과정을 거친다.

데이터를 이동시키는 것이 아닌 새로운 노드를 생성하고 새 노드의 레퍼런스 변수(next)가 head 노드를 가리키도록 해주면 된다. 그럼 위 그림처럼 구현을 해보자.
public void addFirst(E value) {
Node<E> newNode = new Node<E>(value); // 새 노드 생성
newNode.next = head; // 새 노드의 다음 노드로 head 노드를 연결
head = newNode; // head가 가리키는 노드를 새 노드로 변경
size++;
/**
* 다음에 가리킬 노드가 없는 경우(=데이터가 새 노드밖에 없는 경우)
* 데이터가 한 개(새 노드)밖에 없으므로 새 노드는 처음 시작노드이자
* 마지막 노드다. 즉 tail = head 다.
*/
if (head.next == null) {
tail = head;
}
}
위 그림처럼 새 노드(newNode)를 하나 만들어준 다음 '가장 앞에 추가'해야 하므로 기존에 있던 head가 가리키는 노드 앞에 존재해야 한다는 것이다.
즉, 새로운 노드의 next가 다음 노드인 head가 되는 것이다.
그렇게 링크를 연결해주었다면, head가 가리키는 첫번 째 노드를 새로운 노드로 변경해주고 사이즈를 1 증가시키면 된다.
그리고 예외적으로 아무런 노드가 없는 상태에서 처음으로 추가하는 노드일경우는 결국 head가 가리키는 노드는 없다. 이는 head 노드(새로운 노드)가 처음이자 마지막 노드가 된다는 말이기 때문에 마지막을 가리키는 변수 tail은 곧 head와 같은 노드를 가리키게 된다.
2. 기본삽입 : add(E value) & addLast(E value) 메소드
add()의 기본 값은 addLast()라고 했다. 그리고 LinkedLIst API를 보면 add메소드를 호출하면 add() 메소드는 addLast()를 호출한다. 즉, 구현 자체는 addLast를 중점적으로 구현하면 되는 것이다.
그림으로 보자면 다음과 같다.

그리고 여기서 addFirst()를 먼저 구현한 이유가 나오는데, size가 0일 경우(=아무런 노드가 없는 경우)는 결국 처음으로 데이터를 추가한다는 뜻이기 때문에 addFirst()를 호출해주면 된다.
데이터를 이동시키는 것이 아닌 새로운 노드를 생성하고 이전 노드의 레퍼런스 변수(next)가 새로운 노드를 가리키도록 해주면 된다.
@Override
public boolean add(E value) {
addLast(value);
return true;
}
public void addLast(E value) {
Node<E> newNode = new Node<E>(value); // 새 노드 생성
if (size == 0) { // 처음 넣는 노드일 경우 addFisrt로 추가
addFirst(value);
return;
}
/**
* 마지막 노드(tail)의 다음 노드(next)가 새 노드를 가리키도록 하고
* tail이 가리키는 노드를 새 노드로 바꿔준다.
*/
tail.next = newNode;
tail = newNode;
size++;
}
기존에 있던 tail 노드가 다음 노드를 가리키는 변수(next)를 새 노드를 가리키도록 변경해주고 tail이 가리키는 노드를 새로운 노드로 변경만 해주면 된다. 이 부분은 어렵지 않게 구현할 수 있었을 것이다.
3. add(int index, E value)
이 부분이 가장 처리 할 것이 많다. 넣으려는 위치의 앞 뒤로 링크를 새로 업데이트 해주어야 하기 때문이다. 일단 그림을 먼저 보도록 하자.

먼저 넣으려는 위치(예시에서는 index = 3)의 노드와 이전의 노드를 찾아야 한다.
넣으려는 위치의 이전노드를 prev_Node라고 하고, 넣으려는 위치의 기존노드를 next_Node라고 할 때,
앞서 우리가 만든 메소드 search()를 사용하여 넣으려는 위치의 -1 위치의 노드(prev_Node)를 찾아내고, next_Node는 prev_Node.next 를 통해 찾는다.
그리고 prev_Node의 링크를 새로 추가하려는 노드로 변경하고, 새로 추가하려는 노드의 링크는 next_Node로 변경해주는 것이다.
다만 index 변수가 잘못된 위치를 참조할 수 있으니 이에 대한 예외처리로 IndexOutOfBoundsException을 한다.
코드로 보면 이렇다.
@Override
public void add(int index, E value) {
// 잘못된 인덱스를 참조할 경우 예외 발생
if (index > size || index < 0) {
throw new IndexOutOfBoundsException();
}
// 추가하려는 index가 가장 앞에 추가하려는 경우 addFirst 호출
if (index == 0) {
addFirst(value);
return;
}
// 추가하려는 index가 마지막 위치일 경우 addLast 호출
if (index == size) {
addLast(value);
return;
}
// 추가하려는 위치의 이전 노드
Node<E> prev_Node = search(index - 1);
// 추가하려는 위치의 노드
Node<E> next_Node = prev_Node.next;
// 추가하려는 노드
Node<E> newNode = new Node<E>(value);
/**
* 이전 노드가 가리키는 노드를 끊은 뒤
* 새 노드로 변경해준다.
* 또한 새 노드가 가리키는 노드는 next_Node로
* 설정해준다.
*/
prev_Node.next = null;
prev_Node.next = newNode;
newNode.next = next_Node;
size++;
}
이렇게 기본적인 요소 추가 메소드들을 만들어보았다.
[add 메소드 묶어보기]
public void addFirst(E value) {
Node<E> newNode = new Node<E>(value);
newNode.next = head;
head = newNode;
size++;
if (head.next == null) {
tail = head;
}
}
@Override
public boolean add(E value) {
addLast(value);
return true;
}
public void addLast(E value) {
Node<E> newNode = new Node<E>(value);
if (size == 0) {
addFirst(value);
return;
}
tail.next = newNode;
tail = newNode;
size++;
}
@Override
public void add(int index, E value) {
if (index > size || index < 0) {
throw new IndexOutOfBoundsException();
}
if (index == 0) {
addFirst(value);
return;
}
if (index == size) {
addLast(value);
return;
}
Node<E> prev_Node = search(index - 1);
Node<E> next_Node = prev_Node.next;
Node<E> newNode = new Node<E>(value);
prev_Node.next = null;
prev_Node.next = newNode;
newNode.next = next_Node;
size++;
}
[remove 메소드 구현]
add로 요소를 추가했다면 반대로 삭제할 수도 있어야한다.
remove() 메소드 또한 그리 어렵지는 않다. 쉽게 생각해서 add() 메소드의 메커니즘을 반대로 생각하면 된다.
remove 메소드의 경우 크게 3가지로 나눌 수 있다.
- 가장 앞의 요소(head)를 삭제 - remove()
- 특정 index의 요소를 삭제 - remove(int index)
- 특정 요소를 삭제 - remove(Object value)
기본적으로 삭제연산의 가장 기초는 remove()메소드로 head가 가리키는 요소, 즉 첫 번째 요소를 삭제하는 것이다. 인덱스로 생각한다면 0 위치에 있는 요소를 말한다. 그리고 다른 remove()메소드들을 구현할 때 자칫 null을 참조하거나 잘못된 참조를 하는 경우도 있으니 자세히 고민하면서 짜야한다.
1. remove() 메소드
remove() 는 '가장 앞에 있는 요소'를 제거하는 것이다. 즉, head 가 가리키는 요소만 없애주면 된다는 뜻이다.
그림으로 보자면 다음과 같다.

쉽게 생각해서 head가 가리키는 노드의 링크와 데이터를 null로 지워준 뒤 head를 다음 노드로 업데이트를 해주는 것이다.
그리고 삭제하려는 노드가 리스트에서의 유일한 노드였을 경우 해당 노드를 삭제하면 tail이 가리키는 노드 또한 없어지게 된다. (요소가 한 개일 경우 head와 tail이 가리키는 노드가 같기 때문) 이에 대해서도 정확하게 처리를 해주어야 한다.
public E remove() {
Node<E> headNode = head;
if (headNode == null)
throw new NoSuchElementException();
// 삭제된 노드를 반환하기 위한 임시 변수
E element = headNode.data;
// head의 다음 노드
Node<E> nextNode = head.next;
// head 노드의 데이터들을 모두 삭제
head.data = null;
head.next = null;
// head 가 다음 노드를 가리키도록 업데이트
head = nextNode;
size--;
/**
* 삭제된 요소가 리스트의 유일한 요소였을 경우
* 그 요소는 head 이자 tail이었으므로
* 삭제되면서 tail도 가리킬 요소가 없기 때문에
* size가 0일경우 tail도 null로 변환
*/
if(size == 0) {
tail = null;
}
return element;
}
참고로 리스트에 아무런 요소가 없는데 삭제를 시도하려는 경우 요소를 찾을 수 없기 때문에 NoSuchElementException() 예외를 던져주도록 하겠다.
2. remove(int index) 메소드
remove(int index) 메소드는 사용자가 원하는 특정 위치(index)를 리스트에서 찾아서 삭제하는 것이다.
add(int index, E value) 와 정반대로 구현해주면 된다.
쉽게 생각해보자면 삭제하려는 노드의 이전 노드의 next 변수를 삭제하려는 노드의 다음 노드를 가리키도록 해주면 된다.
잘 상상이 안된다면 그림을 보도록 하자.
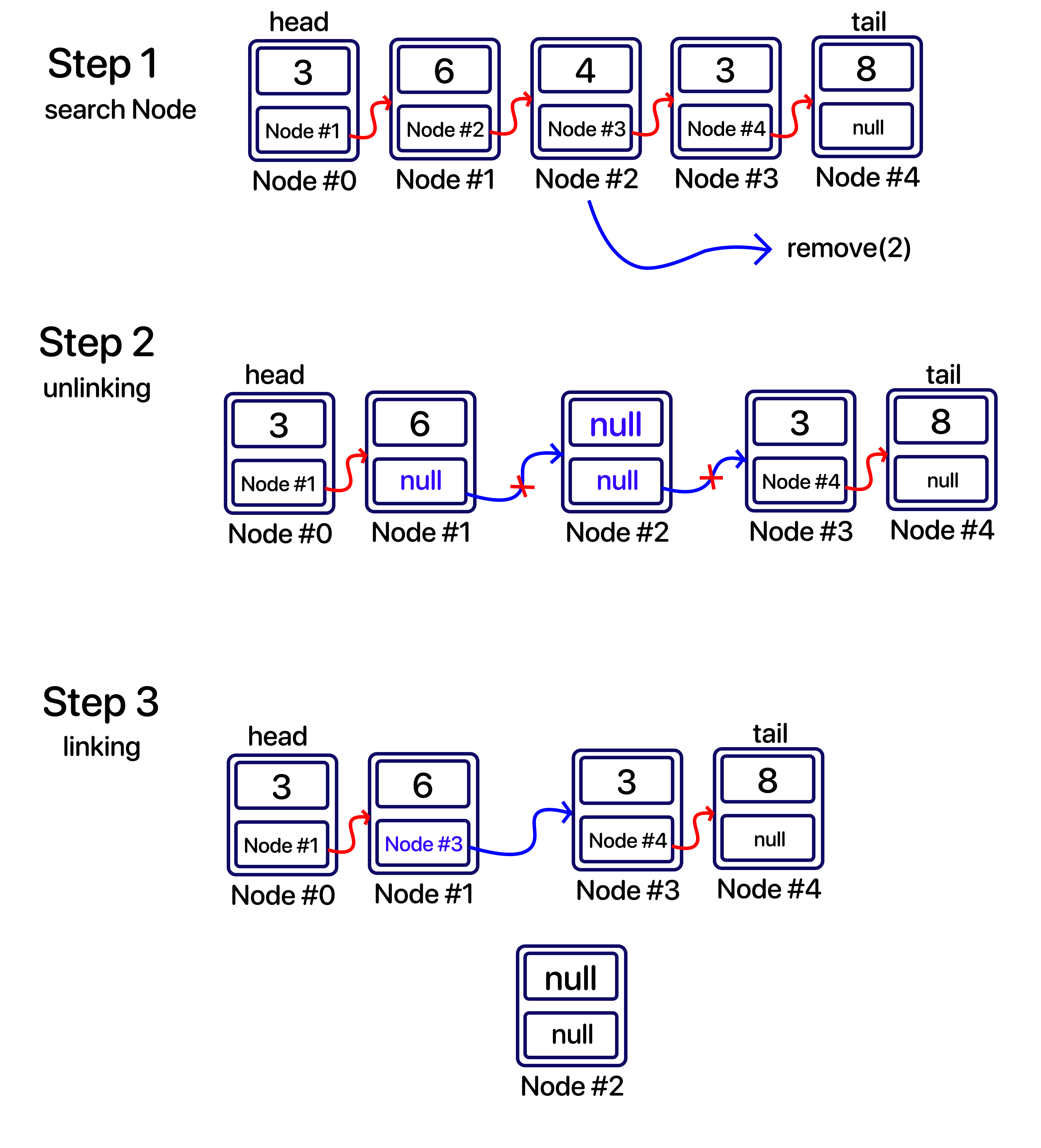
결과적으로 우리가 알아야 할 노드는 총 3개다.
그리고 index를 범위 밖으로 입력했을 경우의 예외 또한 던져주도록 하자.
@Override
public E remove(int index) {
// 삭제하려는 노드가 첫 번째 원소일 경우
if (index == 0) {
return remove();
}
// 잘못된 범위에 대한 예외
if (index >= size || index < 0) {
throw new IndexOutOfBoundsException();
}
Node<E> prevNode = search(index - 1); // 삭제할 노드의 이전 노드
Node<E> removedNode = prevNode.next; // 삭제할 노드
Node<E> nextNode = removedNode.next; // 삭제할 노드의 다음 노드
E element = removedNode.data; // 삭제되는 노드의 데이터를 반환하기 위한 임시변수
// 이전 노드가 가리키는 노드를 삭제하려는 노드의 다음노드로 변경
prevNode.next = nextNode;
// 만약 삭제했던 노드가 마지막 노드라면 tail을 prevNode로 갱신
if(prevNode.next == null) {
tail = prevNode;
}
// 데이터 삭제
removedNode.next = null;
removedNode.data = null;
size--;
return element;
}
참고로 노드를 얻기 위해 기존에 우리가 만들어두었던 search() 메소드를 이용하면 쉽게 얻을 수 있다.
3. remove(Object value) 메소드
remove(Object value) 메소드는 사용자가 원하는 특정 요소(value)를 리스트에서 찾아서 삭제하는 것이다.
remove(int index) 메소드하고 동일한 메커니즘으로 작동한다. 다만 고려해야 할 점은 '삭제하려는 요소가 존재하는지'를 염두해두어야 한다. 예로들어 삭제하려는 요소를 찾지 못했을 경우 false를 반환해주고, 만약 찾았을 경우 remove(int index) 와 동일한 삭제 방식을 사용하면 된다.

코드로 보면 이렇다.
@Override
public boolean remove(Object value) {
Node<E> prevNode = head;
boolean hasValue = false;
Node<E> x = head; // removedNode
// value 와 일치하는 노드를 찾는다.
for (; x != null; x = x.next) {
if (value.equals(x.data)) {
hasValue = true;
break;
}
prevNode = x;
}
// 일치하는 요소가 없을 경우 false 반환
if(x == null) {
return false;
}
// 만약 삭제하려는 노드가 head라면 기존 remove()를 사용
if (x.equals(head)) {
remove();
return true;
}
else {
// 이전 노드의 링크를 삭제하려는 노드의 다음 노드로 연결
prevNode.next = x.next;
// 만약 삭제했던 노드가 마지막 노드라면 tail을 prevNode로 갱신
if(prevNode.next == null) {
tail = prevNode;
}
x.data = null;
x.next = null;
size--;
return true;
}
}
이 부분은 그리 어렵지 않게 구현 할 수 있었을 것이다.
이렇게 요소를 삭제하는 remove 메소드들을 만들어보았다. 해당 메소드들을 묶어서 한 눈에 보고싶다면 아래 더보기를 누르면 된다.
[remove 메소드 묶어보기]
public E remove() {
Node<E> headNode = head;
if (headNode == null)
throw new NoSuchElementException();
E element = headNode.data;
Node<E> nextNode = head.next;
head.data = null;
head.next = null;
head = nextNode;
size--;
if(size == 0) {
tail = null;
}
return element;
}
@Override
public E remove(int index) {
if (index == 0) {
return remove();
}
if (index >= size || size < 0) {
throw new IndexOutOfBoundsException();
}
Node<E> prevNode = search(index - 1);
Node<E> removedNode = prevNode.next;
Node<E> nextNode = removedNode.next;
E element = removedNode.data;
prevNode.next = nextNode;
if(prevNode.next == null) {
tail = prevNode;
}
removedNode.next = null;
removedNode.data = null;
size--;
return element;
}
@Override
public boolean remove(Object value) {
Node<E> prevNode = head;
boolean hasValue = false;
Node<E> x = head; // removedNode
for (; x != null; x = x.next) {
if (value.equals(x.data)) {
hasValue = true;
break;
}
prevNode = x;
}
if(x == null) {
return false;
}
if (x.equals(head)) {
remove();
return true;
}
else {
prevNode.next = x.next;
if(prevNode.next = null) {
tail = prevNode;
}
x.data = null;
x.next = null;
size--;
return true;
}
}
[get, set, indexOf, contains 메소드 구현]
추가와 삭제 메소드는 끝났다. 사실상 50%정도 완료했다고 봐도 된다. 이제 부가기능이지만 매우 중요한 메소드 몇 개를 구현해보고자 한다.
1. get(int index) 메소드
get()은 리스트를 써본 사람이라면 누구나 쉽게 알 것이다. index 로 들어오는 값을 인덱스삼아 해당 위치에 있는 요소를 반환하는 메소드다.
그런데 잘 생각해보자. 우리는 앞서 search() 메소드를 구현해놓았다. 이를 이용하면 되지 않겠는가?
다만 차이점이라면 search() 메소드는 '노드'를 반환하고, get() 메소드는 '노드의 데이터'를 반환한다는 것이다. 즉 아래와 같이 손쉽게 구현할 수 있다.
@Override
public E get(int index) {
return search(index).data;
}
그리고 search() 내부에서 잘못된 위치일 경우 예외를 던지기 때문에 따로 예외처리를 해줄 필요는 없다.
2. set(int index, E value) 메소드
set 메소드는 기존에 index에 위치한 데이터를 새로운 데이터(value)으로 '교체'하는 것이다. add메소드는 데이터 '추가'인 반면에 set은 '교체'라는 점을 기억해두도록 하자.
결과적으로 index에 위치한 데이터를 교체하는 것이기 때문에 마찬가지로 search() 메소드를 사용하여 노드를 찾아내고, 해당 노드의 데이터만 새로운 데이터로 변경해주면 된다.
@Override
public void set(int index, E value) {
Node<E> replaceNode = search(index);
replaceNode.data = null;
replaceNode.data = value;
}
마찬가지로 잘못된 인덱스를 참조하고 있진 않은지 반드시 검사가 필요하다. 그러나 search() 메소드 안에서 인덱스 검사를 해주기 때문에 이 부분은 따로 구현을 하지 않아도 된다.
3. indexOf(Object value) 메소드
indexOf 메소드는 사용자가 찾고자 하는 요소(value)의 '위치(index)'를 반환하는 메소드다.
그러면 이러한 질문이 들어올 수 있다. "찾고자 하는 요소가 중복된다면 어떻게 반환해야 하나요?" 이에 대한 답은 가장 먼저 마주치는 요소의 인덱스를 반환한다는 것이다. (실제로 자바에서 제공하는 indexOf 또한 동일하게 구현된다.)
"그럼 찾고자 하는 요소가 없다면요?" 이러한 경우 -1 을 반환한다.
그리고 중요한 점은 객체끼리 비교할 때는 동등연산자(==)가 아니라 반드시 .equals() 로 비교해야 한다. 객체끼리 비교할 때 동등연산자를 쓰면 값을 비교하는 것이 아닌 주소를 비교하는 것이기 때문에 잘못된 결과를 초래한다.
@Override
public int indexOf(Object value) {
int index = 0;
for (Node<E> x = head; x != null; x = x.next) {
if (value.equals(x.data)) {
return index;
}
index++;
}
// 찾고자 하는 요소를 찾지 못했을 경우 -1 반환
return -1;
}
4. contains(Object value) 메소드
indexOf 메소드는 사용자가 찾고자 하는 요소(value)의 '위치(index)'를 반환하는 메소드였다면, contains는 사용자가 찾고자 하는 요소(value)가 존재 하는지 안하는지를 반환하는 메소드다.
찾고자 하는 요소가 존재한다면 true를, 존재하지 않는다면 false를 반환한다.
음? 그러면 indexOf와 기능이 비슷하니깐 이를 쓸 수 있을 것 같은데? 라는 생각이 들었다면 매우 정답이다.
어차피 해당 요소가 존재하는지를 '검사'한다는 기능은 같기 때문에 indexOf 메소드를 이용하여 만약 음수가 아닌 수가 반환되었다면 요소가 존재한다는 뜻이고, 음수(-1)이 나왔다면 요소가 존재하지 않는다는 뜻이다. 즉, 아래와 같이 contains 메소드를 만들 수 있다.
@Override
public boolean contains(Object item) {
return indexOf(item) >= 0;
}
이렇게 get, set, indexOf, contains 메소드들을 만들어보았다. 해당 메소드들을 묶어서 한 눈에 보고싶다면 아래 더보기를 누르면 된다.
[get, set, indexOf, contains 메소드 묶어보기]
@Override
public E get(int index) {
return search(index).data;
}
@Override
public void set(int index, E value) {
Node<E> replaceNode = search(index);
replaceNode.data = null;
replaceNode.data = value;
}
@Override
public int indexOf(Object value) {
int index = 0;
for (Node<E> x = head; x != null; x = x.next) {
if (value.equals(x.data)) {
return index;
}
index++;
}
return -1;
}
@Override
public boolean contains(Object item) {
return indexOf(item) >= 0;
}
[size, isEmpty, clear 메소드 구현]
이제 나머지 List 인터페이스에 있던 size, isEmpty, clear를 만들 차례다.
다른 메소드 구현에 비해 매우 쉬운지라 바로바로 넘어가도록 하겠다.
1. size() 메소드
ArrayList에서도 말했지만, 모든 리스트 자료구조는 기본적으로 동적 할당을 전제로 한다. 즉 그만큼 요소들을 삽입, 삭제가 많아지면 사용자가 리스트에 담긴 요소의 개수가 몇 개인지 기억하기 힘들다. 더군다나 리스트의 변수들은 기본적으로 private 접근제한자로 size 또한 마찬가지다. (왜냐하면 size를 접근할 수 있게 될 경우 size에 사용자가 고의적으로 데이터를 조작할 수 있기 때문이다.)
그렇기에 size 변수의 값을 반환해주는 메소드인 size() 를 만들어줄 필요가 있다. size만 반환해주면 되기 때문에 매우 간단하다.
@Override
public int size() {
return size;
}
2. isEmpty() 메소드
isEmpty() 메소드는 현재 ArrayList에 요소가 단 하나도 존재하지 않고 비어있는지를 알려준다.
리스트가 비어있을 경우 true를, 비어있지 않고 단 한개라도 요소가 존재 할 경우 false를 반환해주면 된다. 즉, 이 말은 size가 요소의 개수였으므로 size == 0 이면 true, 0 이 아니면 false 라는 것이다. 굳이 배열을 모두 순회하여 데이터가 존재하는지 검사해줄 필요가 없다.
@Override
public boolean isEmpty() {
return size == 0;
}
3. clear() 메소드
clear()는 단어에서 짐작 할 수 있듯 모든 요소들을 비워버리는 작업이다. 예로들어 리스트에 요소를 담아두었다가 초기화가 필요할 때 쓸 수 있는 유용한 존재다. 또한 모든 요소를 비워버린다는 것은 요소가 0개라는 말로 size 또한 0으로 초기화해준다.
이 때 그냥 객체 자체를 null 해주기 보다는 모든 노드를 하나하나 null 해주는 것이 자바의 가비지 컬렉터가 명시적으로 해당 메모리를 안쓴다고 인지하기 떄문에 메모리 관리 효율 측면에서 조금이나마 더 좋다.
@Override
public void clear() {
for (Node<E> x = head; x != null;) {
Node<E> nextNode = x.next;
x.data = null;
x.next = null;
x = nextNode;
}
head = tail = null;
size = 0;
}
이렇게 size, isEmpty, clear 메소드들을 만들어보았다. 해당 메소드들을 묶어서 한 눈에 보고싶다면 아래 더보기를 누르면 된다.
[size, isEmpty, clear 메소드 묶어보기]
@Override
public int size() {
return size;
}
@Override
public boolean isEmpty() {
return size == 0;
}
@Override
public void clear() {
for (Node<E> x = head; x != null;) {
Node<E> nextNode = x.next;
x.data = null;
x.next = null;
x = nextNode;
}
head = tail = null;
size = 0;
}
<부가 목록>
[clone, toArray, sort 메소드 구현]
리스트 인터페이스에서 선언한 메소드는 모두 구현이 되었다. 그래서 이 부분은 굳이 구현하는데 중요한 부분은 아니라 넘어가도 된다. 다만 조금 더 많은 기능을 원할 경우 추가해주면 좋은 메소드들이긴 하다. clone은 기존에 있던 객체를 파괴하지 않고 요소들이 동일한 객체를 새로 하나 만드는 것이다. 그리고 toArray는 리스트를 출력할 때 for-each문을 쓰기 위해 만들어보았다. (만약 for-each문을 구현하고 싶다면 Iterable을 구현해주어야 하지만, 너무 내용이 길어진다. 궁금하신 분은 필자가 깃허브에도 코드를 올리니, 그 코드를 보고 참고해주시면 된다.)
그리고 마지막으로 SLinkedList를 정렬해주고 싶을 때 쓰는 sort() 메소드다.
1. clone() 메소드
만약 사용자가 사용하고 있던 LinkedList를 새로 하나 복제하고 싶을 때 쓰는 메소드다. ArrayList에서도 언급했지만 단순히 = 연산자로 객체를 복사하게 되면 '주소'를 복사하는 것이기 때문에 복사한 객체에서 데이터를 조작할 경우 원본 객체까지 영향을 미친다. 즉 얕은 복사(shallow copy)가 된다는 것이다. (참고로 Object클래스에 정의된 toString() 메소드는 getClass().getName() + "@" + Integer.toHexString(hashCode()); 이다.)
SLinkedList<Integer> original = new SLinkedList<>();
original.add(10); // original에 10추가
SLinkedList<Integer> copy = original;
copy.add(20); // copy에 20추가
System.out.println("original list");
for(int i = 0; i < original.size(); i++) {
System.out.println("index " + i + " data = " + original.get(i));
}
System.out.println("copy list");
for(int i = 0; i < copy.size(); i++) {
System.out.println("index " + i + " data = " + copy.get(i));
}
System.out.println("original list reference : " + original);
System.out.println("copy list reference : " + copy);
[결과]

보다시피 객체의 주소가 복사되는 것이기 때문에 주소와 데이터 모두 같아져버리는 문제가 발생한다.
이러한 것을 방지하기 위해서 깊은 복사를 하는데, 이 때 필요한 것이 바로 clone()이다. Object에 있는 메소드이지만 접근제어자가 protected로 되어있어 우리가 만든 것 처럼 사용자 클래스의 경우 Cloneable 인터페이스를 implement 해야한다.
즉, public class LinkedList<E> implements List<E> 에 Cloneable도 추가해주어야 한다. 만약 안하고서 구현하면 CloneNotSupportedException 에러가 난다.
그리고나서 clone()을 구현하면 되는데, 다음과 같이 재정의를 하면 된다.
public Object clone() throws CloneNotSupportedException {
@SuppressWarnings("unchecked")
SLinkedList<? super E> clone = (SLinkedList<? super E>) super.clone();
clone.head = null;
clone.tail = null;
clone.size = 0;
for (Node<E> x = head; x != null; x = x.next) {
clone.addLast(x.data);
}
return clone;
}
super.clone() 을 해주면, 객체 자체는 생성되나 내부까지 데이터 복제가 이루어지는 것이 아닌 얕은복사가 되어버린다. 그렇기 때문에 새로 만들어진 객체의 내부에 데이터를 새로 설정해주어야 한다.
즉, 각 노드를 일단 끊고, 처음부터 끝까지 현재 리스트의 데이터를 clone 리스트에 넣어주어야 한다.
설명을 덧붙이자면, super.clone() 자체가 생성자 비슷한 역할이고 shallow copy를 통해 사실상 new SLinkedList() 를 호출하는 격이라 제대로 완벽하게 복제하려면 clone한 리스트의 array 또한 새로 생성해서 해당 배열에 copy를 해주어야 한다.
위와같이 만들고 나서 clone()한 것 까지 포함해서 테스트를 해보자.
SLinkedList<Integer> original = new SLinkedList<>();
original.add(10); // original에 10추가
SLinkedList<Integer> copy = original;
SLinkedList<Integer> clone = (SLinkedList<Integer>) original.clone();
copy.add(20); // copy에 20추가
clone.add(30); // clone에 30추가
System.out.println("original list");
for(int i = 0; i < original.size(); i++) {
System.out.println("index " + i + " data = " + original.get(i));
}
System.out.println("\ncopy list");
for(int i = 0; i < copy.size(); i++) {
System.out.println("index " + i + " data = " + copy.get(i));
}
System.out.println("\nclone list");
for(int i = 0; i < clone.size(); i++) {
System.out.println("index " + i + " data = " + clone.get(i));
}
System.out.println("\noriginal list reference : " + original);
System.out.println("copy list reference : " + copy);
System.out.println("clone list reference : " + clone);
[결과]

결과적으로 clone으로 복사한 SLinkedList는 원본 배열에 영향을 주지 않는다.
2. toArray() 메소드
toArray() 또한 앞서 구현한 ArrayList와 마찬가지로 크게 두 가지가 있다.
하나는 아무런 인자 없이 현재 있는 리스트를 객체배열(Object[]) 로 반환해주는 Object[] toArray() 메소드가 있고,
다른 하나는 리스트를 이미 생성 된 다른 배열에 복사해주고자 할 때 쓰는 T[] toArray(T[] a) 메소드가 있다.
즉 차이는 이런 것이다.
SLinkedList<Integer> list = new SLinkedList<>();
// get list to array (using toArray())
Object[] array1 = list.toArray();
// get list to array (using toArray(T[] a)
Integer[] array2 = new Integer[10];
array2 = list.toArray(array2);
1번의 장점이라면 SLinkedList에 있는 요소의 수만큼 정확하게 배열의 크기가 할당되어 반환된다는 점이다.
2번의 장점이라면 객체 클래스로 상속관계에 있는 타입이거나 Wrapper(Integer -> Number) 같이 데이터 타입을 유연하게 캐스팅할 여지가 있다는 것이다. 또한 리스트에 원소 5개가 있고, array2 배열에 10개의 원소가 있다면 array2에 0~4 index에 원소가 복사되고, 그 외의 원소는 기존 array2배열에 초기화 되어있던 원소가 그대로 남는다.
그리고 중요한 점이 잇다. 2번처럼 특정 타입의 객체 배열로 받고 싶은 경우 ArrayList의 배열 생성방식과 차이가 있다. ArrayList에서는 내부에서 데이터를 Object[] 배열에 담았기 때문에 데이터 복사가 쉬웠으나, SLinkedList는 '노드'라는 객체에 데이터를 담고있는 연결리스트이기 때문에 노드 자체가 Integer, String 처럼 래퍼클래스나, 사용자가 만든 클래스 같은 데이터를 갖을 수가 없다. 한 마디로 노드의 data 변수가 객체 타입 변수인 것이지 노드 자체가 객체 타입을 갖지 못한다. 그래서 이전처럼 Arrays.copyOf() 메소드나 System.arraycopy를 쓰기 어렵다.
이럴 때 바로 쓸 수 있는 것이 lang.reflect 패키지에 있는 Array 클래스의 도움을 받을 수 있다. 이에 대한 API는 아래 링크로 남겨둘 것이니 참고해보시길 바란다.
docs.oracle.com/en/java/javase/11/docs/api/java.base/java/lang/reflect/Array.html
Array (Java SE 11 & JDK 11 )
docs.oracle.com
Array 클래스에서 사용 할 것은 바로 newInstance 메소드다.

두 메소드 모두 구현해보자면 다음과 같다.
public Object[] toArray() {
Object[] array = new Object[size];
int idx = 0;
for (Node<E> x = head; x != null; x = x.next) {
array[idx++] = (E) x.data;
}
return array;
}
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size) {
// Array.newInstance(컴포넌트 타입, 생성할 크기)
a = (T[]) java.lang.reflect.Array.newInstance(a.getClass().getComponentType(), size);
}
int i = 0;
Object[] result = a;
for (Node<E> x = head; x != null; x = x.next) {
result[i++] = x.data;
}
return a;
}
Object[] toArray() 메소드의 경우 리스트에 있는 요소 개수(size)만큼 복사하여 Object[] 배열을 반환해주는 메소드다. Object가 최상위 타입이기 때문에 배열에 데이터를 그대로 담고 반환해주면 되기 때문에 크게 어렵지 않다.
두 번째 T[] toArray(T[] a) 메소드를 보자.
이 부분은 제네릭 메소드로, 우리가 만들었던 SLinkedList의 E타입하고는 다른 제네릭이다. 예로들어 E Type이 Integer라고 가정하고, T타입은 Object 라고 해보자.
Object는 Integer보다 상위 타입으로, Object 안에 Integer 타입의 데이터를 담을 수도 있다. 이 외에도 사용자가 만든 부모, 자식 클래스 같이 상속관계에 있는 클래스들에서 하위 타입이 상위 타입으로 데이터를 받고 싶을 때 쓸 수 있도록 하기 위함이다.
즉, 상위타입으로 들어오는 객체에 대해서도 데이터를 담을 수 있도록 별도의 제네릭메소드를 구성하는 것이다. 하위 타입, 즉 축소할 경우 Array 클래스에서 예외를 던지기 때문에 이에 대한 별다른 예외를 처리해줄 필요 없다.
그리고 크게 두 가지 경우의 수가 있다.
첫 번째는 파라미터로 주어지는 배열 a가 현재 리스트의 요소보다 작은 경우와, 그 반대의 경우 이렇게 있다.
먼저 들어오는 배열(a)가 현재 리스트의 요소 개수(size)보다 작으면 size에 맞게 a의 공간을 재할당 하면서 리스트에 있던 모든 요소를 복사한다.
쉽게 이해해보면 SLinkedList의 요소(데이터)가 4개 {1, 2, 3, 4} 있다고 치자. 그리고 Object[] copy = new Object[1]라는 배열을 하나 만들었는데, 공간이 한 개 밖에 없다.
그러면 리스트의 요소 1개만 복사하는 것이 아니라 copy 배열의 사이즈가 1에서 4로 증가하여 copy배열에 {1, 2, 3, 4}가 모두 담기게 되는 것이다.
또한 a에 대한 타입을 알기 위해 먼저 getClass().getComponentType() 을 통해 객체가 어떤 유형의 배열인지를 파라미터를 넣고, 배열의 크기를 설정해준다.
그런 다음 a를 얕은 복사을 통한 Object[] 배열을 하나 만들어 해당 배열을 통해 데이터를 넣어준다음 a를 반환한다. 얕은 복사이기 때문에 result 배열에 담으면 자동으로 a배열에도 영향을 미치는 것을 활용한 방법이다.
반대로 파라미터로 들어오는 배열의 크기가 현재 ArrayList에 있는 array보다 크다면 앞 부분부터 array에 있던 요소만 복사해서 a배열에 넣고 반환해주면 된다.
3. sort() 메소드
ArrayList에서는 따로 만들지는 않았다. ArrayList 자체가 내부에서 Object[] 배열을 사용하고 있기 때문에 Arrays.sort() 를 해주면 끝나기 때문이다.
하지만 LinkedList 같은 객체로 연결 된 리스트들은 이와는 조금 다른 방법으로 정렬해야 한다. 객체배열의 경우 Collections.sort()를 사용하게 되는데, 해당 메소드를 뜯어보았다면 알겠지만, Collections.sort() 도 내부에서는 Arrays.sort()를 쓴다.
어떻게 Arrays.sort()를 쓰지? 싶겠지만, 원리는 간단하다. 해당 리스트를 Object[] 배열로 변환시켜 Arrays.sort()를 통해 정렬한 뒤, 정렬된 데이터를 다시 리스트의 노드에서 셋팅을 해주는 것이다.
만약 래퍼(Wrapper) 클래스 타입(ex. Integer, String, Double ...)이라면 따로 Comparator 을 구현해주지 않아도 되지만, 사용자 클래스, 예로들어 Student 클래스를 만든다거나.. 이러한 경우는 사용자가 따로 해당 객체에 Comparable를 구현해주거나 또는 Comparator를 구현해주어 파라미터로 넘겨주어야 한다.
즉, sort() 메소드를 만들 때, 기본적으로 두 가지 경우를 생각해야 한다는 것이다. 첫 번째는 객체에 Comparable이 구현되어 있어 따로 파라미터로 Comparator를 넘겨주지 않는 경우고, 다른 하나는 Comparator을 넘겨주어 정의 된 정렬 방식을 사용하는 경우다.
public void sort() {
/**
* Comparator를 넘겨주지 않는 경우 해당 객체의 Comparable에 구현된
* 정렬 방식을 사용한다.
* 만약 구현되어있지 않으면 cannot be cast to class java.lang.Comparable
* 에러가 발생한다.
* 만약 구현되어있을 경우 null로 파라미터를 넘기면
* Arrays.sort()가 객체의 compareTo 메소드에 정의된 방식대로 정렬한다.
*/
sort(null);
}
@SuppressWarnings({ "unchecked", "rawtypes" })
public void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
int i = 0;
for (Node<E> x = head; x != null; x = x.next, i++) {
x.data = (E) a[i];
}
}
위 코드에서 보듯이 어떠한 형태로든 결국 sort((Comparator<? super E> c) 로 간다. (참고로 상속관계이면서 부모 클래스에서 정렬 방식을 따르는 경우도 생각하여 <? super E>로 하였다. 이러한 경우를 고려하지 않는다면 Comparator<E>로 해주어도 종속관계 영향을 안받는 객체의 경우는 괜찮다.)
그런다음 Object[] 배열로 우리가 만들었던 toArray()를 통해 만들어 주어 Arrays.sort() 메소드를 통해 정렬해준다.
실제로도 Collections.sort() 또한 Arrays.sort()로 보낸다. 잠깐 내부 구현을 들여다보면 이렇다.
[Collections.sort()] - Comparator() 파라미터가 없는 경우

[Collections.sort()] - Comparator() 파라미터가 주어지는 경우

그리고 두 메소드 모두 List 인터페이스의 default 메소드인 sort() 메소드로 보낸다. 해당 내부 구현은 이렇다.
[List.sort()]

다만 필자가 올린 코드와 차이가 있다면, Iterator을 구현하지 않았기 때문에 대신 반복문을 통해 현재 클래스의 노드 데이터를 직접 바꾼다는 것 뿐이다.
Student 클래스를 통해 이름과 성적을 입력받고, 이를 정렬하는 테스트를 해보도록 한다.
<Student 클래스가 Comparable을 구현하지 않았을 경우>
[test.java]
public class test {
public static void main(String[] args) {
SLinkedList<Student> list = new SLinkedList<>();
list.add(new Student("김자바", 92));
list.add(new Student("이시플", 72));
list.add(new Student("조시샵", 98));
list.add(new Student("파이손", 51));
list.sort();
for(int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
class Student {
String name;
int score;
Student(String name, int score){
this.name = name;
this.score = score;
}
public String toString() {
return "이름 : " + name + "\t성적 : " + score;
}
}
[결과]

이렇게 Comparable을 구현하지 않아 해당 객체의 정렬 방법을 몰라 빨갛게 에러를 뱉어준다. 즉, 명시적으로 Arrays.sort()에 정렬 방법을 알려주던가, Student 클래스에 정렬 방법을 구현하던가 해야한다.
<Comparator의 구현을 통해 명시적으로 Arrays.sort()에 파라미터로 넘기는 방법>
[test.java]
import java.util.Comparator;
public class test {
public static void main(String[] args) {
SLinkedList<Student> list = new SLinkedList<>();
list.add(new Student("김자바", 92));
list.add(new Student("이시플", 72));
list.add(new Student("조시샵", 98));
list.add(new Student("파이손", 51));
list.sort(customComp); // Comparator을 파라미터로 넘겨준다.
for(int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
// 사용자 설정 comparator(비교기)
static Comparator<Student> customComp = new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
return o2.score - o1.score;
}
};
}
class Student {
String name;
int score;
Student(String name, int score){
this.name = name;
this.score = score;
}
public String toString() {
return "이름 : " + name + "\t성적 : " + score;
}
}
이렇게 하면 정렬이 될까? 당연하겠지만 된다.
[결과]

<Comparable의 구현을 통해 객체의 정렬 방법을 설정하는 방법>
객체 기본 정렬방식을 설정해주는 방법. 즉 Comparable 구현 방법으로도 가능하다.
public class test {
public static void main(String[] args) {
SLinkedList<Student> list = new SLinkedList<>();
list.add(new Student("김자바", 92));
list.add(new Student("이시플", 72));
list.add(new Student("조시샵", 98));
list.add(new Student("파이손", 51));
list.sort();
for(int i = 0; i < list.size(); i++) {
System.out.println(list.get(i));
}
}
}
class Student implements Comparable<Student> {
String name;
int score;
Student(String name, int score){
this.name = name;
this.score = score;
}
public String toString() {
return "이름 : " + name + "\t성적 : " + score;
}
@Override
public int compareTo(Student o) {
return o.score - this.score;
}
}
이러면 sort() 내부에서 Comparator가 없으니 해당 클래스의 Comparable에서 compareTo() 을 구현한 내용을 찾아 작성한대로 정렬을 해준다.
[결과]

참고로 ArrayList 구현 할 때에도 sort() 메소드를 구현하고 싶다면 위와 같은 방법으로 구현하면 된다.
이렇게 clone, toArray, sort 메소드들을 만들어보았다. 해당 메소드들을 묶어서 한 눈에 보고싶다면 아래 더보기를 누르면 된다.
[clone, toArray, sort 메소드 묶어보기]
public Object clone() throws CloneNotSupportedException {
@SuppressWarnings("unchecked")
SLinkedList<? super E> clone = (SLinkedList<? super E>) super.clone();
clone.head = null;
clone.tail = null;
clone.size = 0;
for (Node<E> x = head; x != null; x = x.next) {
clone.addLast(x.data);
}
return clone;
}
public Object[] toArray() {
Object[] array = new Object[size];
int idx = 0;
for (Node<E> x = head; x != null; x = x.next) {
array[idx++] = (E) x.data;
}
return array;
}
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size) {
a = (T[]) java.lang.reflect.Array.newInstance(a.getClass().getComponentType(), size);
}
int i = 0;
Object[] result = a;
for (Node<E> x = head; x != null; x = x.next) {
result[i++] = x.data;
}
return a;
}
public void sort() {
sort(null);
}
@SuppressWarnings({ "unchecked", "rawtypes" })
public void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
int i = 0;
for (Node<E> x = head; x != null; x = x.next, i++) {
x.data = (E) a[i];
}
}
- 전체 코드
import java.util.Arrays;
import java.util.Comparator;
import java.util.NoSuchElementException;
import Interface_form.List; // 리스트 인터페이스가 있는 패키지다.
/**
*
* @author ST_ (st-lab.tistory.com)
*
* @param <E> the type of elements in this list
*
*/
public class SLinkedList<E> implements List<E>, Cloneable {
private Node<E> head; // 노드의 첫 부분
private Node<E> tail; // 노드의 마지막 부분
private int size; // 요소 개수
// 생성자
public SLinkedList() {
this.head = null;
this.tail = null;
this.size = 0;
}
// 특정 위치의 노드를 반환하는 메소드
private Node<E> search(int index) {
// 범위 밖(잘못된 위치)일 경우 예외 던지기
if(index < 0 || index >= size) {
throw new IndexOutOfBoundsException();
}
Node<E> x = head; // head부터 시작
for (int i = 0; i < index; i++) {
x = x.next; // x노드의 다음 노드를 x에 저장한다.
}
return x;
}
public void addFirst(E value) {
Node<E> newNode = new Node<E>(value); // 새 노드 생성
newNode.next = head; // 새 노드의 다음 노드로 head 노드를 연결
head = newNode; // head가 가리키는 노드를 새 노드로 변경
size++;
/**
* 다음에 가리킬 노드가 없는 경우(=데이터가 새 노드밖에 없는 경우)
* 데이터가 한 개(새 노드)밖에 없으므로 새 노드는 처음 시작노드이자
* 마지막 노드다. 즉 tail = head 다.
*/
if (head.next == null) {
tail = head;
}
}
@Override
public boolean add(E value) {
addLast(value);
return true;
}
public void addLast(E value) {
Node<E> newNode = new Node<E>(value); // 새 노드 생성
if (size == 0) { // 처음 넣는 노드일 경우 addFisrt로 추가
addFirst(value);
return;
}
/**
* 마지막 노드(tail)의 다음 노드(next)가 새 노드를 가리키도록 하고
* tail이 가리키는 노드를 새 노드로 바꿔준다.
*/
tail.next = newNode;
tail = newNode;
size++;
}
@Override
public void add(int index, E value) {
// 잘못된 인덱스를 참조할 경우 예외 발생
if (index > size || index < 0) {
throw new IndexOutOfBoundsException();
}
// 추가하려는 index가 가장 앞에 추가하려는 경우 addFirst 호출
if (index == 0) {
addFirst(value);
return;
}
// 추가하려는 index가 마지막 위치일 경우 addLast 호출
if (index == size) {
addLast(value);
return;
}
// 추가하려는 위치의 이전 노드
Node<E> prev_Node = search(index - 1);
// 추가하려는 위치의 노드
Node<E> next_Node = prev_Node.next;
// 추가하려는 노드
Node<E> newNode = new Node<E>(value);
/**
* 이전 노드가 가리키는 노드를 끊은 뒤
* 새 노드로 변경해준다.
* 또한 새 노드가 가리키는 노드는 next_Node로
* 설정해준다.
*/
prev_Node.next = null;
prev_Node.next = newNode;
newNode.next = next_Node;
size++;
}
public E remove() {
Node<E> headNode = head;
if (headNode == null)
throw new NoSuchElementException();
// 삭제된 노드를 반환하기 위한 임시 변수
E element = headNode.data;
// head의 다음 노드
Node<E> nextNode = head.next;
// head 노드의 데이터들을 모두 삭제
head.data = null;
head.next = null;
// head 가 다음 노드를 가리키도록 업데이트
head = nextNode;
size--;
/**
* 삭제된 요소가 리스트의 유일한 요소였을 경우
* 그 요소는 head 이자 tail이었으므로
* 삭제되면서 tail도 가리킬 요소가 없기 때문에
* size가 0일경우 tail도 null로 변환
*/
if(size == 0) {
tail = null;
}
return element;
}
@Override
public E remove(int index) {
// 삭제하려는 노드가 첫 번째 원소일 경우
if (index == 0) {
return remove();
}
// 잘못된 범위에 대한 예외
if (index >= size || size < 0) {
throw new IndexOutOfBoundsException();
}
Node<E> prevNode = search(index - 1); // 삭제할 노드의 이전 노드
Node<E> removedNode = prevNode.next; // 삭제할 노드
Node<E> nextNode = removedNode.next; // 삭제할 노드의 다음 노드
E element = removedNode.data; // 삭제되는 노드의 데이터를 반환하기 위한 임시변수
// 이전 노드가 가리키는 노드를 삭제하려는 노드의 다음노드로 변경
prevNode.next = nextNode;
// 만약 삭제했던 노드가 마지막 노드라면 tail을 prevNode로 갱신
if(prevNode.next == null) {
tail = prevNode;
}
// 데이터 삭제
removedNode.next = null;
removedNode.data = null;
size--;
return element;
}
@Override
public boolean remove(Object value) {
Node<E> prevNode = head;
boolean hasValue = false;
Node<E> x = head; // removedNode
// value 와 일치하는 노드를 찾는다.
for (; x != null; x = x.next) {
if (value.equals(x.data)) {
hasValue = true;
break;
}
prevNode = x;
}
// 일치하는 요소가 없을 경우 false 반환
if(x == null) {
return false;
}
// 만약 삭제하려는 노드가 head라면 기존 remove()를 사용
if (x.equals(head)) {
remove();
return true;
}
else {
// 이전 노드의 링크를 삭제하려는 노드의 다음 노드로 연결
prevNode.next = x.next;
// 만약 삭제했던 노드가 마지막 노드라면 tail을 prevNode로 갱신
if(prevNode.next == null) {
tail = prevNode;
}
x.data = null;
x.next = null;
size--;
return true;
}
}
@Override
public E get(int index) {
return search(index).data;
}
@Override
public void set(int index, E value) {
Node<E> replaceNode = search(index);
replaceNode.data = null;
replaceNode.data = value;
}
@Override
public int indexOf(Object value) {
int index = 0;
for (Node<E> x = head; x != null; x = x.next) {
if (value.equals(x.data)) {
return index;
}
index++;
}
// 찾고자 하는 요소를 찾지 못했을 경우 -1 반환
return -1;
}
@Override
public boolean contains(Object item) {
return indexOf(item) >= 0;
}
@Override
public int size() {
return size;
}
@Override
public boolean isEmpty() {
return size == 0;
}
@Override
public void clear() {
for (Node<E> x = head; x != null;) {
Node<E> nextNode = x.next;
x.data = null;
x.next = null;
x = nextNode;
}
head = tail = null;
size = 0;
}
public Object clone() throws CloneNotSupportedException {
@SuppressWarnings("unchecked")
SLinkedList<? super E> clone = (SLinkedList<? super E>) super.clone();
clone.head = null;
clone.tail = null;
clone.size = 0;
for (Node<E> x = head; x != null; x = x.next) {
clone.addLast(x.data);
}
return clone;
}
public Object[] toArray() {
Object[] array = new Object[size];
int idx = 0;
for (Node<E> x = head; x != null; x = x.next) {
array[idx++] = (E) x.data;
}
return array;
}
@SuppressWarnings("unchecked")
public <T> T[] toArray(T[] a) {
if (a.length < size) {
// Arrya.newInstance(컴포넌트 타입, 생성할 크기)
a = (T[]) java.lang.reflect.Array.newInstance(a.getClass().getComponentType(), size);
}
int i = 0;
Object[] result = a;
for (Node<E> x = head; x != null; x = x.next) {
result[i++] = x.data;
}
return a;
}
public void sort() {
/**
* Comparator를 넘겨주지 않는 경우 해당 객체의 Comparable에 구현된
* 정렬 방식을 사용한다.
* 만약 구현되어있지 않으면 cannot be cast to class java.lang.Comparable
* 에러가 발생한다.
* 만약 구현되어있을 경우 null로 파라미터를 넘기면
* Arrays.sort()가 객체의 compareTo 메소드에 정의된 방식대로 정렬한다.
*/
sort(null);
}
@SuppressWarnings({ "unchecked", "rawtypes" })
public void sort(Comparator<? super E> c) {
Object[] a = this.toArray();
Arrays.sort(a, (Comparator) c);
int i = 0;
for (Node<E> x = head; x != null; x = x.next, i++) {
x.data = (E) a[i];
}
}
}
아래 깃허브에서도 소스 코드를 편리하게 보실 수 있다. 또한 깃허브에 올라가는 코드들은 조금 더 기능을 추가하거나 수정되어 올라가기에 약간의 차이는 있을 수 있지만 전체적인 구조는 바뀌지 않으니 궁금하시거나 참고하실 분들은 아래 링크로 가서 보시는 걸 추천한다.
[소스코드 모아보기]
kdgyun/Data_Structure
Contribute to kdgyun/Data_Structure development by creating an account on GitHub.
github.com
- 정리
SLinkedList에 대한 기본적인 메소드를 구현해보았다. 자바에서 제공하고 있는 LinkedList는 양방향 연결리스트이다. 다만, 단일 연결리스트를 먼저 한 이유는 양방향의 경우 고려해야 할 것이 워낙 많고, 기본적인 구조 이해 없이는 어렵기 때문이다.
양방향 연결리스트, 또는 이중 연결리스트라고 불리는 놈은 다음 포스팅에서 보실 수 있다.
어쨌거나, 이번에 구현한 단일 연결리스트의 경우 삽입, 삭제 과정에서 '링크'만 끊어주면 되기 때문에 매우 효율적이라는 것을 볼 수가 있을 것이다.
반대로 모든 자료를 인덱스가 아닌 head부터 연결되어 관리하기 때문에 색인(access)능력은 떨어진다. 결과적으로 이전에 구현했던 ArrayList와 이번에 구현한 LinkedList의 쓰이는 용도가 다르다는 것을 알 수가 있다.
쉽게 생각해서 '삽입, 삭제'가 빈번한 경우 LinkedList를 쓰는 것이 좋고, 데이터 접근이 주를 이룰 경우 ArrayList가 좋다. 두 자료구조의 시간 복잡도는 다음과 같다.

아마 처음 접하는 분들은 제네릭에 대한 이해가 없을경우 좀 어려울 수 있으나, 제네릭을 알면 확장성이 어마무시하게 넓어지기 때문에 꼭 먼저 제네릭에 대해 이해하고 보시는 것을 추천한다.
(그래서 포스팅 상단에 제네릭과 그 외 기타 글들을 같이 링크로 올려두었으니 참고하면서 보면 좋겠다.)
만약 제네릭을 쓰고 싶지 않다면, 위 메소드들에서 제네릭 타입을 여러분이 원하는 타입으로 변경만 해주면 된다.
또한 어렵거나 이해가 안되는 부분, 또는 질문이 있다면 언제든 댓글을 남겨주시면 된다. 최대한 빠르게 답변드리겠다.
'자료구조 > Java' 카테고리의 다른 글
| 자바 [JAVA] - Stack Interface (스택 인터페이스) (12) | 2020.11.19 |
|---|---|
| 자바 [JAVA] - Doubly LinkedList (이중 연결리스트) 구현하기 (12) | 2020.11.18 |
| 자바 [JAVA] - ArrayList (어레이리스트) 구현하기 (42) | 2020.10.29 |
| 자바 [JAVA] - List Interface (리스트 인터페이스) (11) | 2020.10.07 |
| 자바 [JAVA] - 자바 컬렉션 프레임워크 (Java Collections Framework) (50) | 2020.09.21 |