[백준] 9251번 : LCS - JAVA [자바]
9251번: LCS
LCS(Longest Common Subsequence, 최장 공통 부분 수열)문제는 두 수열이 주어졌을 때, 모두의 부분 수열이 되는 수열 중 가장 긴 것을 찾는 문제이다. 예를 들어, ACAYKP와 CAPCAK의 LCS는 ACAK가 된다.
www.acmicpc.net
-
문제

LCS의 대표적인 문제다.
- 알고리즘 [접근 방법]
우리가 그동안 LIS, LDS, 바이토닉 부분수열까지 풀어봤다. 이 번에는 LCS인데, LCS의 정의 자체는 매우 간단하다. 위키피디아에서 보면 매우 잘 정리되어있으니 읽어보시는 것도 좋을 것 같다.
ko.wikipedia.org/wiki/최장_공통_부분_수열
최장 공통 부분 수열 - 위키백과, 우리 모두의 백과사전
위키백과, 우리 모두의 백과사전. 최장 공통 부분수열 문제는 LCS라고도 불린다. 이는 주어진 여러 개의 수열 모두의 부분수열이 되는 수열들 중에 가장 긴 것을 찾는 문제다.(종종 단 두 개중 하�
ko.wikipedia.org
LCS : Longest Common SubSequance
말 그대로 가장 긴(longest) 공통된(Common) 부분수열(subsequance)이다. 좀 더 자세하게 말하자면 임의의 두 수열에서 각각의 부분 수열들 중, 서로 같은 부분 수열 중에서 가장 긴 부분 수열을 의미한다.
문제 예시로 보자면
ACAYKP 의 부분 수열은 (공집합 제외)
{A}, {C}, {A}, {Y}, {K}, {P}, {A, C}, ⋯ , {A, C, A, Y, K, P} 들이 존재하고
CAPCAK 의 부분 수열은
{C}, {A}, {P}, {C}, {A}, {K}, {C, A}, ⋯ , {C, A, P, C, A, K} 들이 존재할 때
각각의 부분 수열 중 서로 같은 부분수열들이 있을 것이다.
예로들면 {A}, {C}, {C, A}, {A, C, A} 등등.. 이들 중에서 가장 긴 공통된 부분 수열을 찾아내는 일이다.
ACAYKP
CAPCAK
위 예시로는 위와 같이 {A,C,A,K} 가 가장 긴 부분수열이 된다.
그럼 어떤 식으로 접근해야 할까? 물론 백트래킹으로 모든 경우의 수를 탐색할 수도 있겠다만, 동적계획법 문제인만큼 메모이제이션을 사용하여 Top-Down방식으로 탐색하거나 Bottom-Up방식을 사용하는 것이 좋겠다.
이러한 LCS문제의 경우 의외로 쉽게 접근할 수 있는데, 부분수열에서 '순서'가 지켜지기 때문에 각 문자열들의 문자들을 서로 비교하면서 서로 같으면 값을 1씩 증가시키면서 누적합을 구하는 것이다.
구체적으로 들여다 보자. 우리는 다음과 같이 테이블을 하나 만들 수 있다. (예제는 위를 토대로 하겠다.)
str1 = ACAYKP
str2 = CAPCAK

그리고 맨 앞 문자부터 차례대로 비교하여 부분수열의 길이를 누적해보자. 그럼 str1의 첫번째 문자인 A를 기준으로 str2의 문자들을 비교해보면 다음과 같다.

여기서 잘 고민해야 할 부분이 [A, A] 의 경우 {C, A} 와 {A}의 LCS 길이를 의미한다. 예로들어 [K, A] 의 경우 {C, A, P, C, A, K} 와 {A}의 LCS길이라는 것이다. 즉 두 번째 A가 오더라도 +1 더하는 것이 아니라 {C, A, P, C, A} 와 {A}의 최장 부분수열은 {A} 하나 뿐이므로 1이 된다.
규칙은 열을 채워나가보면 알 수 있으니 일단은 천천히 채워보도록 하자.
그럼 다음 열을 채워보자

{C} 와 {A, C}의 부분수열은 {C} 이고, 두 번째 C에서는 {C, A, P ,C} 와 {A, C}의 부분 수열은 {A, C}로 +1이 증가한다. 또 한 번 채워볼까.

{C}와 {A, C, A}의 부분수열은 {C}이므로 1이고, {C, A}와 {A, C, A}의 부분수열은 {C, A}이다. 다음 열 Y의 경우는 겹치는 수열이 없기 때문에 이전 열의 값을 그대로 받아올 것이다. 이런식으로 채워나가다보면 다 채웠을 때 다음과 같이 된다.
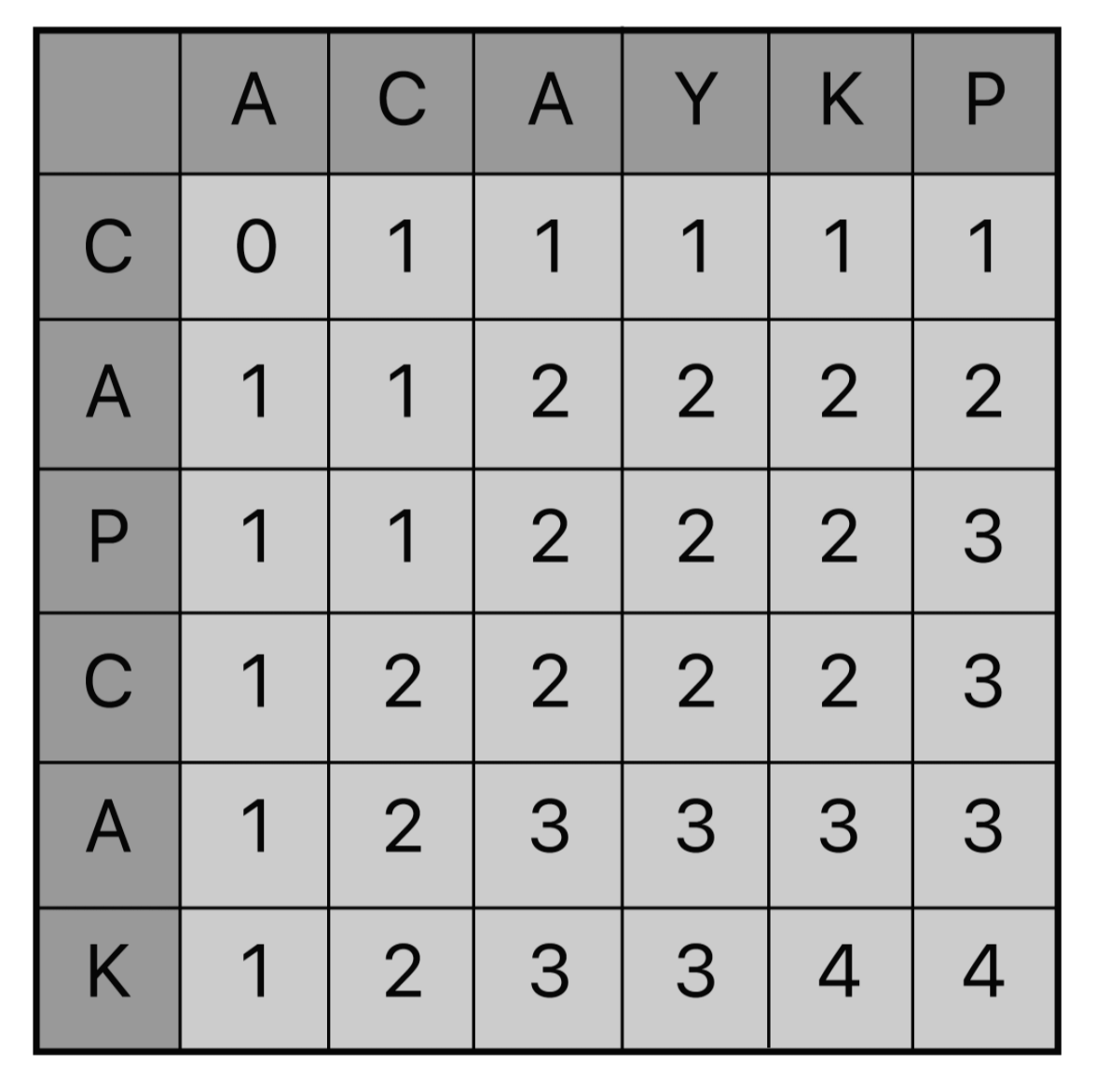
채우다 보면 규칙이 있다. 각 열을 채울 때 같은 원소가 있다면 이전 열 또는 행에 +1 한 값이 LCS 길이가 된다는 것이다. 생각해보자. 아까 채울 때 '부분 수열'에 대한 길이 값을 채워나가는 것이였다.
예로들어 그림에서 (0, 1)을 보자. 이 인덱스는 {C}, {A, C}의 LCS길이를 의미하는 것이고 이는 {C}로 길이는 1이다.
그 다음 (1, 2)를 보자. 이 인덱스는 {C, A} 와 {A, C, A}의 LCS 길이를 의미하는 것이다. 즉, {C}, {A, C} 에서 'A'라는 공통 원소가 추가 된 것이다.
정리하자면 이렇다.
x번째 원소와 y번째 원소가 같다면 (x-1, y-1) 의 LCS길이의 +1이 된다.
만약 같지 않다면? 필자 예시는 열 순서대로 채웠지만 행으로 채워도 마찬가지다. Y열을 채울 때 A까지의 LCS와 다를게 없기 때문에 그대로 갖고왔듯이 말이다. 즉, 이전 행의 원소 또는 열 원소 중 '큰 것'을 기준으로 채우면 된다.
함수로 정의하자면 이렇다.
LCS(Xi, Yj) : LCS(Xi-1, Yj-1) + 1 if (Xi == Yj)
LCS(Xi, Yj) : max( LCS(Xi-1, Yj), LCS(Xi, Yj-1) ) if (Xi != Yj)
위 공식대로 역추적 루트를 그려보면 다음과 같은 루트가 되는 것이다.

각 인덱스별 역추적 경로로 본다면 이렇다. (진한 블록이 실제 경로)
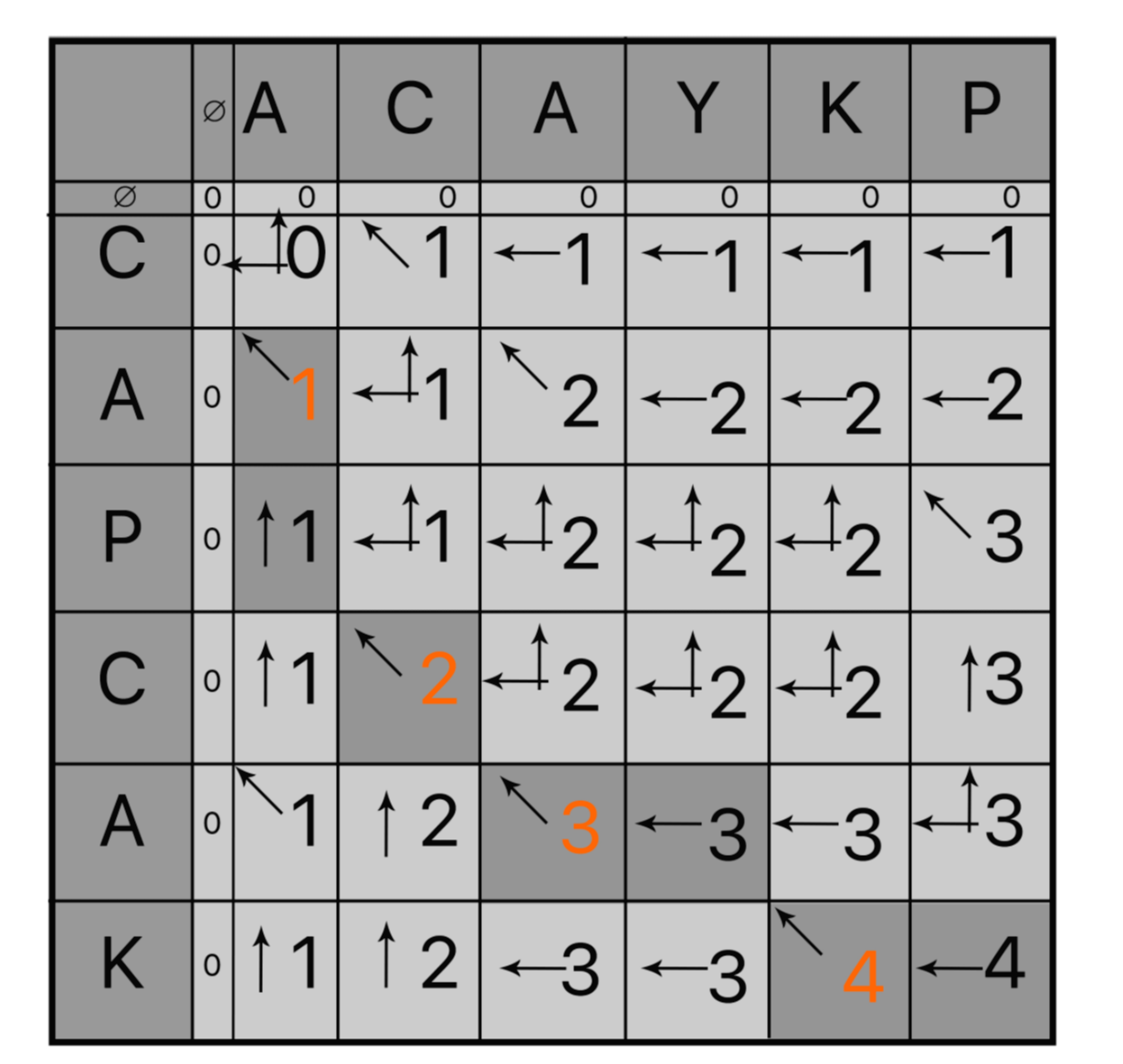
이렇게 백트래킹 형식으로 한다면 위와같이 짤 수 있을 것이다.
그렇다면 문제는 코드를 어떻게 짜느냐다. 위와 같은 테이블을 dp[][] 2차원 배열로 두고, Top-Down의 경우 점화식(함수)만 발견하면 쉽게 구현할 수 있다. 앞서 필자가 언급했던 함수를 다시 되짚어보자.
LCS(Xi, Yj) : LCS(Xi-1, Yj-1) + 1 if (Xi == Yj)
LCS(Xi, Yj) : max( LCS(Xi-1, Yj), LCS(Xi, Yj-1) ) if (Xi != Yj)
그리고 추가로 인덱스 밖(-1)을 참조할 수 없으므로 이 조건까지 추가하여 이를 그대로 재귀형식으로 적용하면 이렇게 될 것이다.
static int LCS(int x, int y) {
// 인덱스 밖 (공집합)일 경우 0 반환
if(x == -1 || y == -1) {
return 0;
}
// 만약 탐색하지 않은 인덱스라면?
if(dp[x][y] == null) {
dp[x][y] = 0;
// str1의 x번째 문자와 str2의 y번째 문자가 같은지 검사
if(str1[x] == str2[y]) {
dp[x][y] = LCS(x - 1, y - 1) + 1;
}
// 같지 않다면 LCS(dp)[x-1][y]와 LCS(dp)[x,y-1] 중 큰 값으로 초기화
else {
dp[x][y] = Math.max(LCS(x - 1, y), LCS(x, y - 1));
}
}
return dp[x][y];
}
매우 간단하게 구현해낼 수 있다. 물론 위 방식인 Top-Down이 아니라 Bottom-Up 방식으로도 쉽게 구현이 가능하다. (오히려 성능 부분에서 더 좋을 수도 있다.)
다만 앞서 우리가 그림으로 봤듯이 재귀의 경우는 분기문으로 인덱스 참조값이 -1 이 되면 0을 반환하면 되지만 for문(반복문)으로 이를 구현하고자 하면 오버헤드 비용이 너무 많이 소모된다. 그렇기 때문에 dp배열을 한 줄씩 늘려 0번째 행과 0번째 열은 위 그림처럼 공집합을 의미하는 행과 열로 나타내주는 것이 가장 현명하다.
말로하면 어려우니 일단 코드를 보면 이렇다.
// 공집합 표현을 위해 인덱스가 한 줄씩 추가 됨
int[][] dp = new int[length_1 + 1][length_2 + 1];
// 1부터 시작 (index 0 은 공집합이므로 0의 값을 갖고있음)
for(int i = 1; i <= length_1; i++) {
for(int j = 1; j <= length_2; j++) {
// (i-1)과 (j-1) 번째 문자가 서로 같다면
if(str1[i - 1] == str2[j - 1]) {
// 대각선 위 (i-1, j-1)의 dp에 +1 한 값으로 갱신
dp[i][j] = dp[i - 1][j - 1] + 1;
}
// 같지 않다면 이전 열(i-1)과 이전 행(j-1)의 값 중 큰 것으로 갱신
else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
특히나 서로 문자가 같을경우 (i-1, j-1)을 참조해야하는데 index가 0부터 시작한다면 -1을 참조해버리기 때문에 위와 같이 1부터 시작하도록 해야한다.
- 4가지 방법을 사용하여 풀이한다.
이전 포스팅과 여타 다를 바 없이 아래와 같이 알고리즘과 입출력 방법을 통해 성능을 비교해보려 한다.
1 . Scanner + Top-Down
2. BufferedReader + Top-Down
3. Scanner + Bottom-Up
4. BufferedReader + Bottom-Up
- 풀이
- 방법 1 : [Scanner + Top-Down]
import java.util.Scanner;
public class Main {
static char[] str1;
static char[] str2;
static Integer[][] dp;
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
// toCharArray() 는 문자열을 char[] 배열로 반환해주는 메소드다.
str1 = in.nextLine().toCharArray();
str2 = in.nextLine().toCharArray();
dp = new Integer[str1.length][str2.length];
System.out.println(LCS(str1.length - 1, str2.length - 1));
}
static int LCS(int x, int y) {
// 인덱스 밖 (공집합)일 경우 0 반환
if(x == -1 || y == -1) {
return 0;
}
// 만약 탐색하지 않은 인덱스라면?
if(dp[x][y] == null) {
dp[x][y] = 0;
// str1의 x번째 문자와 str2의 y번째 문자가 같은지 검사
if(str1[x] == str2[y]) {
dp[x][y] = LCS(x - 1, y - 1) + 1;
}
// 같지 않다면 LCS(dp)[x-1][y]와 LCS(dp)[x,y-1] 중 큰 값으로 초기화
else {
dp[x][y] = Math.max(LCS(x - 1, y), LCS(x, y - 1));
}
}
return dp[x][y];
}
}
위에서도 언급했지만 굳이 한 줄을 읽고 for문으로 char[] 배열 초기화 또는 재귀문에서 charAt()을 통해 참조를 해줄 필요 없이 문자열(String)을 char[] 배열로 바로 반환해주는 메소드를 쓰면 좀 더 깔끔하게 쓸 수 있다.
물론 개인 취향인지라 charAt()으로 참조해주면서 해도 된다.
- 방법 2 : [BufferedReader + Top-Down]
입력 방법을 Scanner 대신 BufferedReader 을 사용하여 풀이하는 방법이다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
public class Main {
static char[] str1;
static char[] str2;
static Integer[][] dp;
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
str1 = br.readLine().toCharArray();
str2 = br.readLine().toCharArray();
dp = new Integer[str1.length][str2.length];
System.out.println(LCS(str1.length - 1, str2.length - 1));
}
static int LCS(int x, int y) {
// 인덱스 밖 (공집합)일 경우 0 반환
if(x == -1 || y == -1) {
return 0;
}
// 만약 탐색하지 않은 인덱스라면?
if(dp[x][y] == null) {
dp[x][y] = 0;
// str1의 x번째 문자와 str2의 y번째 문자가 같은지 검사
if(str1[x] == str2[y]) {
dp[x][y] = LCS(x - 1, y - 1) + 1;
}
// 같지 않다면 LCS(dp)[x-1][y]와 LCS(dp)[x,y-1] 중 큰 값으로 초기화
else {
dp[x][y] = Math.max(LCS(x - 1, y), LCS(x, y - 1));
}
}
return dp[x][y];
}
}
필자는 역시 재귀문으로 쓰는게 편하긴 하다.. 점화식만 알면 되니,,
- 방법 3 : [Scanner + Bottom-Up]
반복문으로 구현한 방법이다. 아마 문자길이가 각각 최대 1000까지 주어지기 때문에 이 알고리즘이 좀 더 빠를 것이다.
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
char[] str1 = in.nextLine().toCharArray();
char[] str2 = in.nextLine().toCharArray();
int length_1 = str1.length;
int length_2 = str2.length;
// 공집합 표현을 위해 인덱스가 한 줄씩 추가 됨
int[][] dp = new int[length_1 + 1][length_2 + 1];
// 1부터 시작 (index 0 은 공집합이므로 0의 값을 갖고있음)
for(int i = 1; i <= length_1; i++) {
for(int j = 1; j <= length_2; j++) {
// (i-1)과 (j-1) 번째 문자가 서로 같다면
if(str1[i - 1] == str2[j - 1]) {
// 대각선 위 (i-1, j-1)의 dp에 +1 한 값으로 갱신
dp[i][j] = dp[i - 1][j - 1] + 1;
}
// 같지 않다면 이전 열(i-1)과 이전 행(j-1)의 값 중 큰 것으로 갱신
else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
// Top-Down 때와는 다르게 dp 인덱스가 한 줄씩 추가되었으므로 -1을 하지 않음
System.out.println(dp[length_1][length_2]);
}
}
알고리즘란에서 설명한 방법 그대로 갖고온 것이니 헷갈릴 것은 없을 것이다.
- 방법 4 : [BufferedReader + Bottom-Up]
입력 방법을 Scanner 대신 BufferedReader 을 사용하여 풀이하는 방법이다. 아마 대중적인 방법에서는 이 방법이 가장 빠를 것이다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
char[] str1 = br.readLine().toCharArray();
char[] str2 = br.readLine().toCharArray();
int length_1 = str1.length;
int length_2 = str2.length;
// 공집합 표현을 위해 인덱스가 한 줄씩 추가 됨
int[][] dp = new int[length_1 + 1][length_2 + 1];
// 1부터 시작 (index 0 은 공집합이므로 0의 값을 갖고있음)
for(int i = 1; i <= length_1; i++) {
for(int j = 1; j <= length_2; j++) {
// (i-1)과 (j-1) 번째 문자가 서로 같다면
if(str1[i - 1] == str2[j - 1]) {
// 대각선 위 (i-1, j-1)의 dp에 +1 한 값으로 갱신
dp[i][j] = dp[i - 1][j - 1] + 1;
}
// 같지 않다면 이전 열(i-1)과 이전 행(j-1)의 값 중 큰 것으로 갱신
else {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]);
}
}
}
System.out.println(dp[length_1][length_2]);
}
}
이해시키기 위해 오랜만에 포토샵으로 그림까지 그려가며 했지만,,, 혹시 이해 안되신다면 댓글 남겨주면 친절히 가르쳐 드리니 꼭 댓글 남겨주시길...
- 성능

채점 번호 : 22401738 - 방법 4 : BufferedReader + Bottom-Up
채점 번호 : 22401730 - 방법 3 : Scanner + Bottom-Up
채점 번호 : 22401721 - 방법 2 : BufferedReader + Top-Down
채점 번호 : 22401713 - 방법 1 : Scanner + Top-Down
음.. 생각보다 알고리즘에서 많이 차이가 난다. 아무래도 오버헤드 비용이 재귀가 높다보니 그럴 것 같다. 메모이제이션을 했지만, for문으로 시간복잡도 O(N), 재귀 시간 복잡도 O(N) 으로 같아보일 순 있으나 메모리에 로드하는 비용이 for문보다 재귀가 훨씬 비싸기 때문이라고 보고 있다.
- 정리
이 번 문제는 LCS 풀이법을 알고있다면 쉽게 풀 수 있으나 처음 접할 경우 조금 어려웠을 수도 있다. 하지만 이 LCS의 풀이방법은 익혀두는 것이 좋다. 이 걸 알아서 어디에다가 쓰냐고 물을 수 있겠다만, 유사도를 볼 때 (유전이라던가 음성 인식 정도?) 사용되는 알고리즘이기도 하다. 예로들어 두 이미지 데이터를 읽어들여 데이터를 LCS 방식으로 유사도를 검증하는 방식이 있다.
혹여 위 글에서 이해가 안되거나 어려운 부분이 있다면 언제든 댓글은 환영이다.
'JAVA - 백준 [BAEK JOON] > 동적 계획법 1' 카테고리의 다른 글
| [백준] 12865번 : 평범한 배낭 - JAVA [자바] (48) | 2020.09.17 |
|---|---|
| [백준] 1912번 : 연속합 - JAVA [자바] (15) | 2020.09.10 |
| [백준] 2565번 : 전깃줄 - JAVA [자바] (11) | 2020.09.04 |
| [백준] 11054번 : 가장 긴 바이토닉 부분 수열 - JAVA [자바] (8) | 2020.09.04 |
| [백준] 11053번 : 가장 긴 증가하는 부분 수열 - JAVA [자바] (17) | 2020.09.02 |