[백준] 15649번 : N과 M (1) - JAVA [자바]
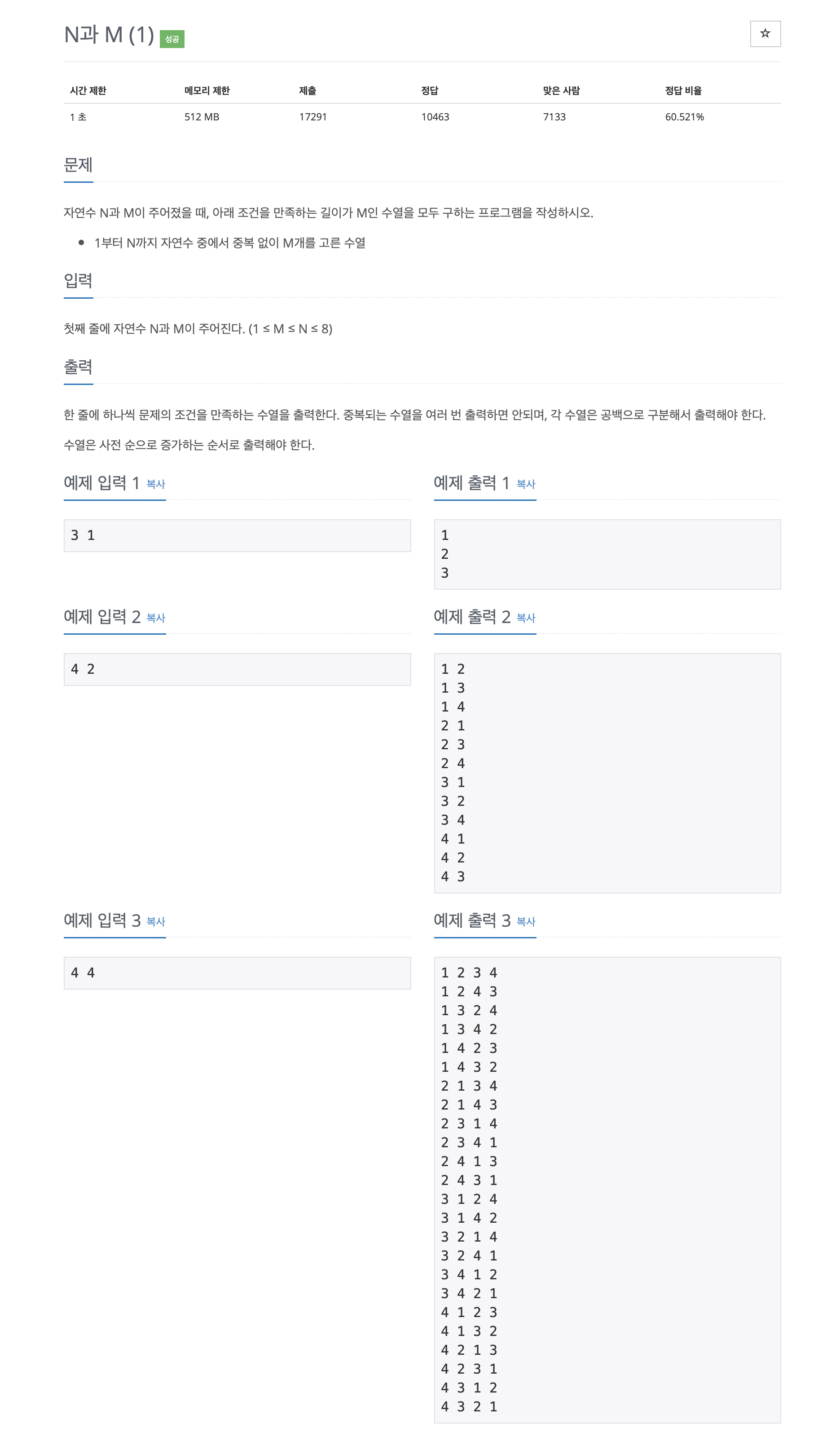
15649번: N과 M (1)
한 줄에 하나씩 문제의 조건을 만족하는 수열을 출력한다. 중복되는 수열을 여러 번 출력하면 안되며, 각 수열은 공백으로 구분해서 출력해야 한다. 수열은 사전 순으로 증가하는 순서로 출력해
www.acmicpc.net
- 문제
백트래킹 카테고리의 첫 문제다.
이러한 문제를 처음 접하는 분들은 약간은 난해할 수는 있지만, 원리만 이해하면 매우 쉬운 문제이니 차근차근 알아보도록하자.
- 알고리즘 [풀이 방법]
백트래킹(Backtracking)에 대해 먼저 간단하게 이해하고 가자.
위 단어를 그대로 해석하고 이해하면 된다. 말 그대로 되추적인데, 좀더 알고리즘적으로 설명하자면, 어떤 노드의 '유망성'을 판단한 뒤, 해당 노드가 유망하지 않다면 부모 노드로 돌아가 다른 자식 노드를 찾는 방법이다. 즉, 모든 경우의 수를 찾아보지만, 그 중에서도 가능성만 있는 경우의 수만 찾아보는 방법이다.
백준 알고리즘에서 단계별로 풀어보았다면, 이전에 브루트포스(Brute-Force)를 배웠을 것이다.
간혹가다 브루트포스와 백트래킹, 그리고 DFS(깊이우선탐색)를 혼동하는 경우가 있어 이에 대해 정리를 한 번 하고 가는게 좋다.
예로들어 이러한 문제가 있다고 가정해보자.
" a + b + c + d = 20 을 만족하는 두 수를 모두 찾아내시오. ( 0 ≤ a ,b ,c ,d < 100) "
이 때 브루트포스는 말 그대로 '모든 경우의 수'를 찾아보는 것이다.
즉, a = 1, b = 1, c =1, d = 1 부터 시작하여 a = 100, b = 100, c = 100, d = 100 까지 총 1억개의 경우의 수를 모두 찾아보면서 a + b + c + d = 20 이 만족하는 값을 탐색하는 것이다. 브루트포스가 강력한 점은 모든 경우의 수를 탐색하다보니 만족하는 값을 100% 찾아낸다는 점이다. 반대로 단점이라면 모든 경우의 수를 판단하는 만큼 조합 가능한 경우의 수가 많으면 많을 수록 자원을 매우 많이 필요로 한다는 점이다.
백트래킹은 앞서 말했듯이 해당 노드의 유망성을 판단한다고 했다. 이 말은 즉 해당 범위 내에서 조건을 추가하여 값의 유망성을 판단한다는 의미이다. 하나라도 a = 21 또는 b = 21 또는 c = 21 또는 d = 21 일 경우 20일 가능성이 1 ~ 100 범위 내에서는 절대 불가능하다. 그렇기 때문에 a > 20 이거나 b > 20, c > 20, d > 20 일 경우는 탐색하지 않는다. 그렇게 된다면 탐색하는데 필요한 자원을 많이 줄일 수 있다.
DFS(깊이우선탐색)은 트리순회의 한 형태다. 하나의 순회 알고리즘으로 백트래킹에 사용하는 대표적인 탐색 알고리즘이다. 즉, 백트래킹 = DFS가 아니라 백트래킹의 방법 중 하나가 DFS인 것이다. 그 외에도 BFS(너비우선탐색) 등 다양한 방법으로 백트래킹을 구현할 수 있다.
DFS 알고리즘을 설명하자면 0 0 0 0, 0 0 0 1, 0 0 0 2, ⋯ 이런식으로 탐색하는 방법인데, 그림으로 보자면 다음과 같다.
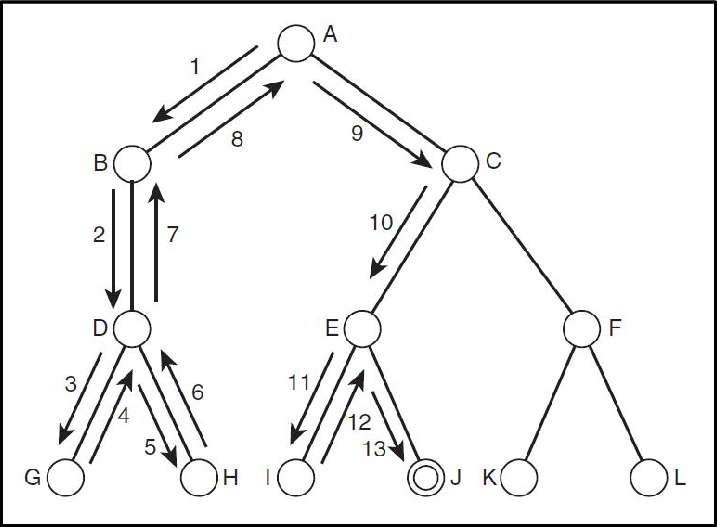
말 그래도 깊이를 우선으로 먼저 탐색하는 방법이다.
즉, 백트래킹 문제를 DFS 방법을 통해 구현하는 것이 이번 문제의 포인트다. 좀 더 구체적인 설명은 나중에 DFS, BFS 카테고리도 있으니 이 때 설명하도록 하겠다.
그럼 이제 어떻게 구현해야하는지가 관건이다. 문제에서 N과 M이 주어지고, 중복되는 수를 제외한 모든 경우의 수를 탐색하면 된다. 그럼 기본적으로 재귀를 통해 풀어볼 수가 있겠다.
이 때 재귀를 하면서 이미 방문한 노드(값)이라면 다음 노드를 탐색하도록 하기 위해(유망한 노드인지 검사하기 위해) N 크기의 boolean 배열을 생성하고, 탐색과정에서 값을 담을 int 배열 arr 을 생성한다.
dfs 함수에는 N과 M을 변수로 받아야하는 건 당연지사, depth 변수를 추가해야한다. depth를 통해 재귀가 깊어질 때마다 depth를 1씩 증가시켜 M과 같아지면 더이상 재귀를 호출하지 않고 탐색과정 중 값을 담았던 arr 배열을 출력해주고 return 하는 역할을 위해서다.
코드로 보면 아래와 같다.
boolean[] visit = new boolean[N];
int[] arr = new int[M];
public static void dfs(int N, int M, int depth) {
// 재귀 깊이가 M과 같아지면 탐색과정에서 담았던 배열을 출력
if (depth == M) {
for (int val : arr) {
System.out.print(val + " ");
}
System.out.println();
return;
}
for (int i = 0; i < N; i++) {
// 만약 해당 노드(값)을 방문하지 않았다면?
if (visit[i] == false) {
visit[i] = true; // 해당 노드를 방문상태로 변경
arr[depth] = i + 1; // 해당 깊이를 index로 하여 i + 1 값 저장
dfs(N, M, depth + 1); // 다음 자식 노드 방문을 위해 depth 1 증가시키면서 재귀호출
// 자식노드 방문이 끝나고 돌아오면 방문노드를 방문하지 않은 상태로 변경
visit[i] = false;
}
}
return;
}
일단 주석으로 설명을 했지만 다시 한번 설명하자면, 중복되는 수는 담을수 없기에 방문할 필요조차 없다. 즉, 방문 상태를 판단하기 위해 visit[] 배열이 있는 것이고, 해당 index가 방문하지 않는 노드(값)일 때만 재귀호출을 해주면 된다. 이게 백트래킹의 가장 기초라 할 수 있다.
물론 N과 M 을 함수 인자로 안넘겨도 된다. N과 M은 자체 값이 변경되거나 할 일이 없기 때문에 전역변수로 바꾸어도 무방하다. 이에 대한 것은 마지막 방법에서 설명하겠다. (자바에서는 static이라는 정적 키워드를 이용하여 전역변수처럼 활용할 수 있다. main 메소드는 static 메소드라 정적 메소드에서 외부 변수를 쓰려면 해당 변수 또한 정적 변수여야 하기 때문에 main 밖의 변수 또한 static이 붙는다. 그래서 혼용하여 쓰기 때문에 일단 이 글에서는 정적변수 = 전역변수 라고 생각하고 읽도록 하자)
- 4가지 방법을 이용하여 풀이한다.
알고리즘은 위의 알고리즘을 그대로 사용하면 된다.
즉, dfs 함수에 N과 M, 그리고 depth 는 깊이가 0부터 시작하므로 0을 인자로 넘겨주면 된다.
다만, 입출력을 다르게 해볼 것인데, 3가지 방법은 아래와 같다.
1. Scanner + System.out.print()
2. Scanner + StringBuilder
3. BufferedReader + StringBuilder
4. BufferedReader + StringBuilder + N과 M 전역변수화
위 4가지 방법을 통해 성능 차이를 보고자 한다.
그리고 마지막 4번의 경우 N과 M 을 넘겨주지 않고 전역변수로 바꾼 뒤, dfs 함수 피라미터를 한 개만 쓰는 방법도 보여주겠다.
- 풀이
- 방법 1 : [Scanner + System.out.print()]
import java.util.Scanner;
public class Main {
public static int[] arr;
public static boolean[] visit;
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int N = in.nextInt();
int M = in.nextInt();
arr = new int[M];
visit = new boolean[N];
dfs(N, M, 0);
}
public static void dfs(int N, int M, int depth) {
if (depth == M) {
for (int val : arr) {
System.out.print(val + " ");
}
System.out.println();
return;
}
for (int i = 0; i < N; i++) {
if (!visit[i]) {
visit[i] = true;
arr[depth] = i + 1;
dfs(N, M, depth + 1);
visit[i] = false;
}
}
}
}
가장 기본적인 방법이라 할 수 있겠다.
그리고 재귀호출할 때 매우 주의해야할 점이 있다.
간혹 depth + 1 이 아니라 depth++ 을 해줘서 틀리는 사람이 꽤 여럿 있는데, 이렇게 하면 dfs 재귀호출 다음 줄에 depth--을 해주지 않으면 안된다.
depth + 1 과 depth++ 은 똑같이 1은 증가시켜주지만 작동원리는 다르다.
depth++ 은 depth 변수의 값 자체가 1 증가하기 때문에 재귀에서 빠져나와도 증가된 값은 그대로 유지된다. 반면에 depth + 1 은 자바 내부에서 임시로 depth + 1 값을 복사하여 해당 값을 사용하기 때문에 재귀에서 빠져나오면 depth + 1 값이 발화된다.
그러니 이 점을 유의하여 사용하시길 바란다.
- 방법 2 : [Scanner + StringBuilder]
출력을 매번 해줄 필요 없이 하나의 문자열로 묶어서 출력하는 방법이다. 기본적으로 입출력 자체가 자원을 많이 소모하기 때문에 반복적인 출력보다는 하나의 문자열로 연결해주는 것이 시간소모가 덜하다.
알고리즘은 같으므로 알고리즘에서 설명할 것은 딱히 없을 듯 하다.
import java.util.Scanner;
public class Main {
public static int[] arr;
public static boolean[] visit;
public static StringBuilder sb = new StringBuilder(); // 정적타입으로 해주어야한다.
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int N = in.nextInt();
int M = in.nextInt();
arr = new int[M];
visit = new boolean[N];
dfs(N, M, 0);
// 마지막에 한 번에 출력
System.out.println(sb);
}
public static void dfs(int N, int M, int depth) {
if (depth == M) {
for (int val : arr) {
sb.append(val).append(' ');
}
sb.append('\n');
return;
}
for (int i = 0; i < N; i++) {
if (!visit[i]) {
visit[i] = true;
arr[depth] = i + 1;
dfs(N, M, depth + 1);
visit[i] = false;
}
}
}
}
- 방법 3 : [BufferedReader + StringBuilder]
사실 BufferedReader 을 쓰는 분들이라면 출력문이 길 경우 대부분 BufferedWriter 나 StringBuilder 을 사용하여 출력하기 때문에 System.out.print 반복출력 방법을 굳이 보여줄 필요가 없을 것 같다고 생각한다.
그래서 BufferedReader 입력방법과 StringBuilder 을 통한 출력방법을 사용하는 것만 보도록 할 것이다.
그리고 문자열 분리를 위해 StringTokenizer 을 사용하겠다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.util.StringTokenizer;
public class Main {
public static int[] arr;
public static boolean[] visit;
public static StringBuilder sb = new StringBuilder();
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int N = Integer.parseInt(st.nextToken());
int M = Integer.parseInt(st.nextToken());
arr = new int[M];
visit = new boolean[N];
dfs(N, M, 0);
System.out.println(sb);
}
public static void dfs(int N, int M, int depth) {
if (depth == M) {
for (int val : arr) {
sb.append(val).append(' ');
}
sb.append('\n');
return;
}
for (int i = 0; i < N; i++) {
if (!visit[i]) {
visit[i] = true;
arr[depth] = i + 1;
dfs(N, M, depth + 1);
visit[i] = false;
}
}
}
}
쉽지 않은가?? 음.. 아마 브루트포스와 재귀 카테고리를 거쳐왔다면 대부분 금방 이해하실 것이다. 혹여 이해가 안간다면 댓글 남겨주시면 최대한 빨리 답변드리겠다.
- 방법 4 : [BufferedReader + StringBuilder + N과 M 전역변수화]
앞서 잠깐 언급했듯이 사실 N과 M은 함수 인자로 넘겨줄 필요가 없다.
(다만 이해하기 쉬우라고 넘겨준 것일뿐)
N과 M은 값이 변경되지 않고 재귀와 반복문의 조건으로써만 쓰이기 때문에 차라리 전역변수로 두고, 인자를 depth만 넘겨서 사용해도 문제가 되지 않는다. 아니 오히려 코드는 깔끔해진다. 아래 코드를 보면 바로 이해할 수 있을 것이다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.util.StringTokenizer;
public class Main {
public static int N; // 정적변수로 변경
public static int M; // 정적변수로 변경
public static int[] arr;
public static boolean[] visit;
public static StringBuilder sb = new StringBuilder();
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
// 정적변수 N과 M을 초기화해준다.
N = Integer.parseInt(st.nextToken());
M = Integer.parseInt(st.nextToken());
arr = new int[M];
visit = new boolean[N];
// 정적변수를 쓰면 되기 때문에 굳이 N과 M을 넘겨줄 필요 없다.
dfs(0);
System.out.println(sb);
}
public static void dfs(int depth) {
if (depth == M) {
for (int val : arr) {
sb.append(val).append(' ');
}
sb.append('\n');
return;
}
for (int i = 0; i < N; i++) {
if (!visit[i]) {
visit[i] = true;
arr[depth] = i + 1;
dfs(depth + 1);
visit[i] = false;
}
}
}
}
앞으로는 N과 M이 별다르게 수정될 일이 없다면 이 방법대로 풀 것이다. 이번 포스팅은 첫 백트래킹 문제인 만큼 기본 방법을 설명하기 위해 N과 M을 피라미터로 넘겨주었지만, 사실 별다른 조건이 없다면 그냥 정적변수화 해도 상관이 없다.
단 특정 조건이 있을 경우는 정적변수로 쓰면 안되므로 기본 방법과 이 방법 둘 다 익혀두도록 하자.
- 성능

위에서 부터 순서대로
채점 번호 : 20544456 - 방법 4 : BufferedReader + StringBuilder + N과 M 전정변수화
채점 번호 : 20544453 - 방법 3 : BufferedReader + StringBuilder
채점 번호 : 20544450 - 방법 2 : Scanner + StringBuilder
채점 번호 : 20544447 - 방법 1 : Scanner + System.out.print()
입출력에 따라 성능이 꽤 차이나는 것을 볼 수 있다. 특히 출력차이가 꽤 많이 난다.
- 정리
백트래킹의 가장 기초 문제를 DFS 를 통해 풀어보았다.
기본적으로 백트래킹, 재귀에 대한 이해를 필요로 하기에 이에 대한 이해는 정확하게 하고 가는 것을 추천한다. 만약 이해가 안되는 부분이 있다면 댓글 남겨주면 늦어도 하루 이내로 답변드리도록 노력하고 있으니 부담없이 물어보셔도 된다.
'JAVA - 백준 [BAEK JOON] > 백트래킹' 카테고리의 다른 글
| [백준] 2580번 : 스도쿠 - JAVA [자바] (44) | 2020.07.09 |
|---|---|
| [백준] 9663번 : N-Queen - JAVA [자바] (51) | 2020.07.08 |
| [백준] 15652번 : N과 M (4) - JAVA [자바] (4) | 2020.07.03 |
| [백준] 15651번 : N과 M (3) - JAVA [자바] (4) | 2020.06.29 |
| [백준] 15650번 : N과 M (2) - JAVA [자바] (10) | 2020.06.26 |