[백준] 1181번 : 단어 정렬 - JAVA [자바]
1181번: 단어 정렬
첫째 줄에 단어의 개수 N이 주어진다. (1≤N≤20,000) 둘째 줄부터 N개의 줄에 걸쳐 알파벳 소문자로 이루어진 단어가 한 줄에 하나씩 주어진다. 주어지는 문자열의 길이는 50을 넘지 않는다.
www.acmicpc.net
- 문제

이전 좌표정렬하기 문제를 풀어보았다면 이 문제 또한 매우 간단한 문제다!
※ 주의할 점
- 단어 길이순으로 정렬한 뒤, 길이가 같을 경우 사전순으로 정렬해야한다.
- 중복되는 단어가 있을경우 한 번만 출력한다.
- 알고리즘 [접근 방법]
이전 포스팅에서도 말했지만 배열을 특정한 규칙에 의해 정렬하고 싶은 경우 Arrays.sort 메소드에 Comparator 을 구현하면 된다고 했다.
(만약 보지 못한 분들을 위해 아래 링크를 클릭하면 된다.)
[백준] 11650번 : 좌표 정렬하기 - JAVA [자바]
www.acmicpc.net/problem/11650 1546번: 평균 첫째 줄에 시험 본 과목의 개수 N이 주어진다. 이 값은 1000보다 작거나 같다. 둘째 줄에 세준이의 현재 성적이 주어진다. 이 값은 100보다 작거나 같은 음이 아닌
st-lab.tistory.com
몇 분이 Comparator 의 compare 메소드를 람다식으로 구현하는 방법까지는 어려워 하는 듯 하여 이번에는 Arrays.sort 에 Comparator 을 써서 compare 메소드를 구현하는 방법으로 접근해보겠다. 이 방법을 알면 자연스레 람다식으로 쓰는 법도 이해 될 것이다.
그리고 위 포스팅을 꼭 읽어보시길 바란다. 이번에는 아주 간략하게만 설명할 것이다.
일단 간략하게 설명하자면 Arrays.sort() 는 단순 배열을 오름차순으로 정렬해주는 것 뿐만 아니라 사용자에 의해 구현할 수 있다. Java API 문서를 보면 Arrays.sort() 메소드 목록 중 아래와 같은 것도 있다.
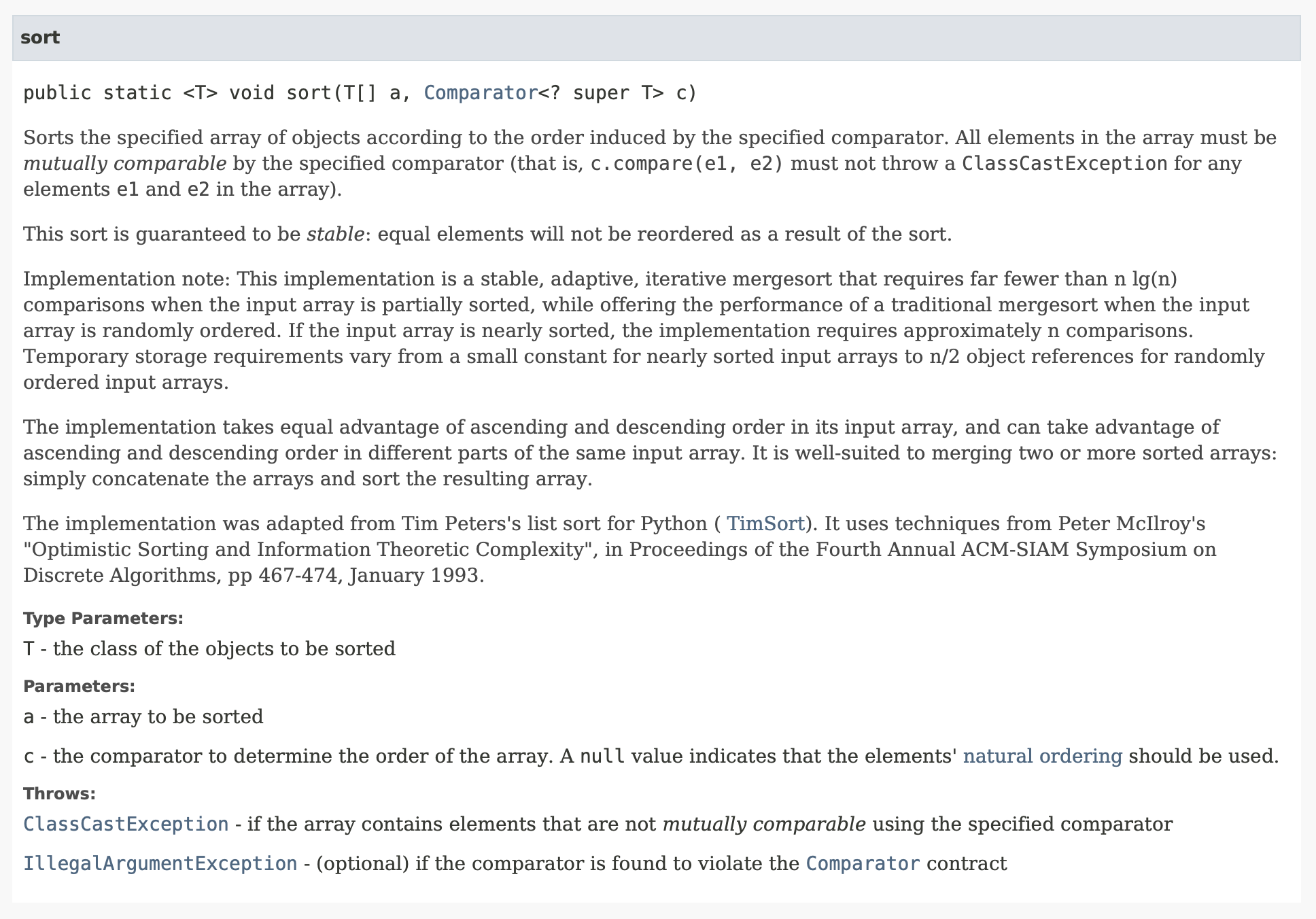
여기서 Comparator<? super T> c 에 대해 이해가 있어야 한다.
Arrays.sort() 메소드 안에는 두 객체(원소)를 비교하여 위치를 바꿀지 말지 판단하면서 정렬을 한다.
기본적으로 Comparator는 객체를 비교할 수 있도록 해주는 인터페이스다. 보통 int, char, double 등의 자바에서 제공하는 자료형들은 비교가 가능하지만, 여러분이 사용자 클래스를 만들어 비교한다거나, 특정 규칙에 의해 비교를 하고 싶은 경우에는 Comparator를 구현해야 한다.
일단 간단하게 설명만 하자면, <? super T> 는 상속관계에 있는 타입만 자료형으로 받겠다는 의미이고, 이 말인 즉 T 타입이 자식클래스가 되고, T의 상속관계에 있는 타입까지만 허용하겠다는 의미다. 이해가 안된다면 일단은 물음표는 생략하고 <T> 이렇게 생각하셔도 된다.
더 쉽게 말하자면 T = Type 을 의미하며 객체, 자료형 등의 다양한 타입 중 하나를 설정 할 수 있다는 것이다.
우리가 해야할 것은 단어 정렬이니 기본적으로 정렬할 배열의 타입은 String 이 될 것이다. 즉 T 는 String 이 된다는 것이다.
이렇게 Comparator 의 타입을 넣었으면, 다음으로 해야할 것은 compare 메소드를 오버라이딩하는 것이다. 즉, 아래 코드가 기본형이 되겠다.
String[] arr = new String[N]; // 배열에 단어가 이미 초기화 되었다고 가정
Arrays.sort(arr, new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
/*
정렬방법 구현
*/
}
});
그리고 compare 메소드 리턴 타입이 왜 int 형이냐고 한다면, 기본적으로 compare 메소드는 3가지 리턴 값에 의해 위치를 바꿀지 결정하게 된다. 3가지 리턴 값이라 하면 다음과 같다.
- 양의 정수
- 0
- 음의 정수
기본적으로 양수일경우 Arrays.sort()에서 정렬 알고리즘에 의해 위치를 바꾸고, 0 이나 음의 정수인 경우는 두 객체의 위치는 바뀌지 않는다.
예로들어 { 2, 1, 3 } 이라는 배열이 있고, public int compare(int a1, int a2) { return a1 - a2 } 가 있다고 가정해보자.
그렇다면 맨 처음 a1 은 2 가 될테고, a2 는 1이 된다. 즉, 2 - 1 = 1 이므로 양수가 반환되기 때문에 a1 과 a2, 즉 2 와 1 의 위치가 서로 바뀌게 된다. 그러면 { 1, 2, 3 } 이 되겠다.
그 다음 a1, a2 는 각각 2 와 3이 될테고, 2 - 3 = -1 이므로 음수가 반환되어 두 객체 2와 3은 위치가 바뀌지 않는다.
이렇게 compare 메소드는 3가지 반환값에 의해 두 객체(인자)의 우선순위를 판단하고, 이를 정렬알고리즘 안에서 위치를 바꾸거나 그대로 둔다.
그러면 본격적으로 구현해보자. 위 코드에서 안에 정렬 방법만 작성하면 끝이다.
먼저 조건을 보면 1차 조건은 '단어 길이' 순이다. 만약 단어 길이가 같을 경우 이 때 '사전순'으로 정렬하면 된다. 그러면 compare 메소드에서 if 조건문을 통해 단어길이를 비교후 같을 경우 사전순으로 정렬하도록 하고, 그 외에는 단어 길이순으로 정렬하면 되겠다. 코드를 보면 아래와 같다.
String[] arr = new String[N]; // 배열에 단어가 이미 초기화 되었다고 가정
Arrays.sort(arr, new Comparator<String>() {
@Override
public int compare(String s1, String s2) {
// 단어 길이가 같을 경우
if(s1.length() == s2.length()} {
return s1.compareTo(s2); // 사전 순 정렬
}
// 그 외의 경우
else {
return s1.length() - s2.length();
}
}
});
단어 사전순 정렬은 대부분 알고있겠지만 compareTo() 메소드를 쓰면 된다. 이 메소드 또한 리턴(반환)값은 int 형으로 나온다.
위 알고리즘을 토대로 풀면 문제는 해결된다.
- 3가지 방법을 이용하여 풀이한다.
위 알고리즘을 토대로 입출력 방법만 바꾸어 각각의 성능 차이를 비교해 볼 것이다.
이전 포스팅과 마찬가지로 아래 3가지 방법을 사용한다.
Scanner + System.out.println
Scanner + StringBuilder
BufferedReader + StringBuilder
- 풀이
- 방법 1 : [Scanner + System.out.println]
Scanner 를 쓸 때 정말 주의해야 할 점이 있다.
필자가 Scanner 에 대해 포스팅을 썼을 때 언급했지만, 기본적으로 서로 다른 자료형을 받고싶은 경우 어떤 형을 먼저 받냐에 따라 자칫 에러가 날 수 있다고 했다. (모르시는 분은 아래 글 참고)
st-lab.tistory.com/92#next_nextLine
자바 [JAVA] - 스캐너(Scanner) 클래스와 입력
자바를 처음 배울 때 아마 대부분은 키보드로 입력받기 위해 Scanner 라는 클래스를 썼을 것이다. 자바 외에도 다양한 언어들은 각각의 입력방식이 있고, 각 언어별로 대표하는 대중적인 입력방식
st-lab.tistory.com
콘솔창에서도 실행해보면 알겠지만, nextInt() 로 정수를 입력받은 뒤, nextLine() 을 쓰면 입력한 첫 번째 문자가 arr[0] 에 입력되는 것이 아니라 개행("\n")이 arr[0] 에 저장된다. 이는 next 계열 입력을 받은 뒤, nextLine() 을 쓰면 두 메소드의 메커니즘이 달라 발생하는 대표적인 에러다. 그러니 이 점 유의하여 입력되는 개행을 한 번 버려야 정상적으로 입력한 문자열을 배열에 저장할 수 있다.
import java.util.Scanner;
import java.util.Arrays;
import java.util.Comparator;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int N = in.nextInt();
String[] arr = new String[N];
in.nextLine(); // 개행 버림
for (int i = 0; i < N; i++) {
arr[i] = in.nextLine();
}
Arrays.sort(arr, new Comparator<String>() {
public int compare(String s1, String s2) {
// 단어 길이가 같을 경우
if (s1.length() == s2.length()) {
return s1.compareTo(s2);
}
// 그 외의 경우
else {
return s1.length() - s2.length();
}
}
});
System.out.println(arr[0]);
for (int i = 1; i < N; i++) {
// 중복되지 않는 단어만 출력
if (!arr[i].equals(arr[i - 1])) {
System.out.println(arr[i]);
}
}
}
}
가장 기본적인 방법이라 할 수 있겠다.
먼저 배열에 모든 원소를 입력받아 저장하고 sort() 를 사용하여 위에서 배웠던 알고리즘을 통해 정렬을 한다.
그러면 기본적으로 길이 순으로 정렬이 되고 길이가 같을 경우는 사전 순으로 정렬이 된다.
이때 출력할 때에는 정렬된 배열에서 출력하려는 문자열이 직전 배열에 있는 문자열과 같지 않을 경우만 출력하여 문제의 조건대로 '중복되는 문자열은 한 번만 출력'하도록 한다.
- 방법 2 : [Scanner + StringBuilder]
출력방법을 바꾸어 StringBuilder 을 사용하여 하나의 문자열로 묶어준 뒤 마지막에 묶어준 문자열을 출력해주는 방법이다.
알고리즘은 바뀌지 않으니 그리 어려운 점은 없을 것이다.
import java.util.Scanner;
import java.util.Arrays;
import java.util.Comparator;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int N = in.nextInt();
String[] arr = new String[N];
in.nextLine(); // 개행 버림
for (int i = 0; i < N; i++) {
arr[i] = in.nextLine();
}
Arrays.sort(arr, new Comparator<String>() {
public int compare(String s1, String s2) {
// 단어 길이가 같을 경우
if (s1.length() == s2.length()) {
return s1.compareTo(s2);
}
// 그 외의 경우
else {
return s1.length() - s2.length();
}
}
});
StringBuilder sb = new StringBuilder();
sb.append(arr[0]).append('\n');
for (int i = 1; i < N; i++) {
// 중복되지 않는 단어만 출력
if (!arr[i].equals(arr[i - 1])) {
sb.append(arr[i]).append('\n');
}
}
System.out.println(sb);
}
}
- 방법 3 : [BufferedReader + StringBuilder]
Scanner 입력 방식 대신 BufferedReader 을 사용한 방법이다. 알고리즘은 위와 동일하니 어려운 점은 딱히 없을 것 같다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
import java.util.Arrays;
import java.util.Comparator;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
String[] arr = new String[N];
for (int i = 0; i < N; i++) {
arr[i] = br.readLine();
}
Arrays.sort(arr, new Comparator<String>() {
public int compare(String s1, String s2) {
// 단어 길이가 같을 경우
if (s1.length() == s2.length()) {
return s1.compareTo(s2);
}
// 그 외의 경우
else {
return s1.length() - s2.length();
}
}
});
StringBuilder sb = new StringBuilder();
sb.append(arr[0]).append('\n');
for (int i = 1; i < N; i++) {
// 중복되지 않는 단어만 출력
if (!arr[i].equals(arr[i - 1])) {
sb.append(arr[i]).append('\n');
}
}
System.out.println(sb);
}
}
생각보다 쉽지 않은가?
물론 BufferedWriter 로 StringBuilder 대신하여 써도 된다. 아마 그렇게 큰 성능차이는 안날 것이다. 이건 뭐 개인의 성향차이니.. 한 번은 써보시는 것도 좋을 것 같다.
- 성능

위에서 부터 순서대로
채점 번호 : 20432462 - 방법 3 : BufferedReader + StringBuilder
채점 번호 : 20432458 - 방법 2 : Scanner + StringBuilder
채점 번호 : 20432455 - 방법 1 : Scanner + System.out.println
입력의 경우는 확실히 Scanner 보다는 BufferedReader 가 빠른 걸 볼 수 있다. 특히 1번과 3번의 시간차는 거의 3배이니 방법 3을 쓰는 걸 매우 적극 추천한다.
- 정리
필자가 문제를 정리하면서 느끼는 것이지만 아무래도 대부분 포스팅을 보는 분들은 검색을 해서 보다보니 필자가 이전 포스팅과 연계하여 포스팅을 하려고 하더라도 이전 포스팅을 보지 않았을 확률이 매우 높다. 이렇다보니 가끔 필자가 설명을 놓치기도 하고, 그렇다고 다른 포스팅에서 잘 정리 되어있는 내용을 중복해서 쓰자니 너무 글이 길어지고 가독성도 떨어진다.
그러니.. 필자가 링크 건 것은 어지간하면 꼭 보고 오셨으면 하는 작은 바램이 있다. 중요한 내용이기도 하고, 무엇보다 여러분들에게 도움이 되는 내용들이니 적극 추천한다.
그리고 언제나 모르는 내용이 있으면 댓글 남겨주면 최대한 빠르게 답변 드리도록 하겠다. 차피 휴대폰으로 알람이 뜨기 때문에 댓글을 못본채 할 수가 없다.
'JAVA - 백준 [BAEK JOON] > 정렬' 카테고리의 다른 글
| [백준] 18870번 : 좌표 압축 - JAVA [자바] (17) | 2021.12.11 |
|---|---|
| [백준] 10814번 : 나이순 정렬 - JAVA [자바] (31) | 2020.06.20 |
| [백준] 11651번 : 좌표 정렬하기 2 - JAVA [자바] (10) | 2020.06.17 |
| [백준] 11650번 : 좌표 정렬하기 - JAVA [자바] (49) | 2020.06.10 |
| [백준] 1427번 : 소트인사이드 - JAVA [자바] (12) | 2020.06.03 |