[백준] 1300번 : K번째 수 - JAVA [자바]
https://www.acmicpc.net/problem/1300
1300번: K번째 수
세준이는 크기가 N×N인 배열 A를 만들었다. 배열에 들어있는 수 A[i][j] = i×j 이다. 이 수를 일차원 배열 B에 넣으면 B의 크기는 N×N이 된다. B를 오름차순 정렬했을 때, B[k]를 구해보자. 배열 A와 B
www.acmicpc.net
- 문제

- 알고리즘 [접근 방법]
필자도 이 번 문제는 접근 방법을 이해하는데 조금 애를 먹은 문제다.
혹여나 필자가 포스팅 하는데, 잘못 접근하진 않았을까 검색도 해보았지만 생각보다 한 번에 이해가 팍 되는 글은 개인적으로 없는 것 같았다.
그래서 최대한 쉽게 풀이하여 이해 할 수 있도록 최대한 노력해보겠다.
일단, 이분 탐색으로 접근한다는 생각은 잠시 뒤로하고 문제부터 하나씩 뜯어보자.
문제의 본질은 다음과 같다. A[i][j] = i * j 로 이루어져있는 행렬들을 1차원 배열 B로 만들 때 B[k]의 값은 무엇인지를 찾는 문제다.
이해가 어렵다면 아래 이미지를 보자.
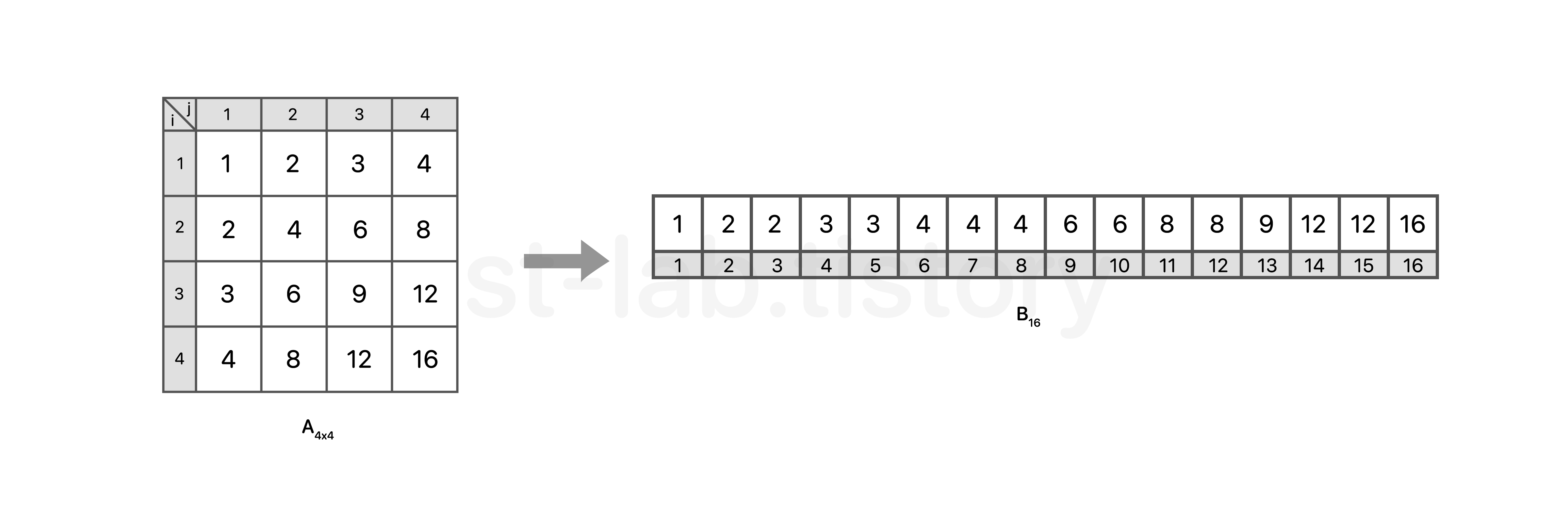
예로들어 4×4 2차원 행렬 A를 1차원 행렬 B로 변환하여 B[K] 의 값을 찾는 문제다.
그래서 예로들어 K=11 이라고 한다면, B[11] = 8 이 되는 것이다.
그럼 이 B[K] 의 값을 어떻게 찾아야 하는가가 관건이다.
일단, 입력으로 주어지는 행 또는 열의 크기 N은 105 로 전체 행렬의 크기는 최대 1010 으로, 10,000,000,000 (100억)이 된다. 이 말은 행렬을 만들어 브루트 포스로 탐색하기에는 너무 많은 메모리와 시간을 잡아먹게 된다는 의미다.
그러면 우리는 다른 접근 방법을 알아보아야 한다. 어떻게 접근 할 수 있을까?
앞서 예로 들었던 B[11] = 8 의 의미를 파악해보자. 기본적인 의미는 B[11] = 8 은 "B행렬의 11번째 값은 8" 이라는 의미일 것이다.
하지만, 거꾸로 "8이라는 값보다 작거나 같은 원소의 개수는 최소 11개"다라는 의미로도 볼 수 있다.
왜 이 것이 가능한가? 위 이미지에서 B행렬을 보면 '단조 증가 행렬' 즉, 오름차순 성질을 갖고 있다.
이 말은 모든 구간에 대해 B[i] ≤ B[i + 𝛼] 라는 의미이기 때문이다.
정리하자면 B[K] = 𝑥 라는 의미는 𝑥 보다 작거나 같은 원소의 개수가 최소 K개라는 의미다.
예로들어보자. 𝑥=6 일 때, 𝑥보다 작거나 같은 원소의 개수는 몇 개일까?
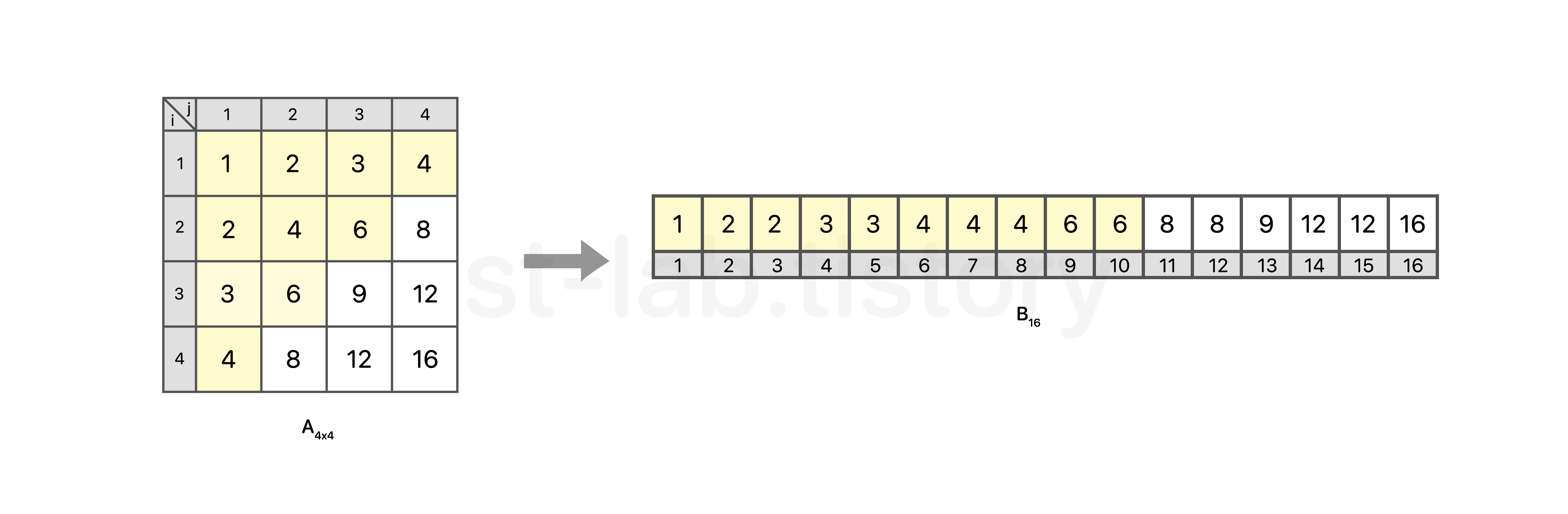
위 이미지에서도 알 수 있듯 6보다 작은 원소의 개수는 10개라는 것을 확인 할 수 있다.
결국, B[K] 에서 K 라는 것은 B[K]의 원소 값보다 작거나 같은 원소의 개수라는 의미가 된다.
여기서 눈치가 빠른 분들은 알겠지만, 이분 탐색을 이용한다고 하면 무엇을 조정해야 하는 것인지 알 수 있다.
우리가 찾고자 하는 것은 B[K] = 𝑥 에서 K인덱스의 원소 값 𝑥 를 찾는 것이다. 그렇다면, 𝑥 의 값을 조정해나가면서 𝑥 보다 작거나 같은 원소의 개수가 K값이랑 일치하면 되는 것이 아닌가?
일단 위의 의미를 이해를 해야 다음으로 넘어 갈 수 있으니 위 접근 방식부터 이해하고 다음 부분으로 넘어가보자.
자, 그러면 위 설명을 통해 알 수 있는 것은 "𝑥 의 값을 조정해나가면서 𝑥 보다 작거나 같은 원소의 개수가 K값이랑 일치"해야 한다는 것이다.
𝑥의 값은 그렇다 쳐도, 어떻게 𝑥 보다 작은 원소들의 개수를 찾을 수 있지? 결국 그러면 행렬을 만들어야 하는 거 아닌가? 생각이 드실 것이다.
잠깐 옛날 옛적 구구단을 배웠을 때로 돌아가보자.
1단 : {1, 2, 3, 4, 5, 6, 7, 8, 9}
2단 : {2, 4, 6, 8, 10, 12, 14, 16, 18}
3단 : {3, 6, 9, 12, 15, 18, 21, 24, 27}
4단 : {4, 8, 12, 16, 20, 24, 28, 32, 36}
5단 : {5, 10, 15, 20, 25, 30, 35, 40, 45}
6단 : {6, 12, 18, 24, 30, 36, 42, 48, 54}
7단 : {7, 14 ,21 ,28, 35, 42, 49, 56, 63}
8단 : {8, 16, 24, 32, 40, 48, 56, 64, 72}
9단 : {9, 18, 27, 36, 45, 54, 63, 72, 81}
자, 여기서 '각 단 별로 8보다 작거나 같은 수의 개수를 찾아보시오' 라고 하면 여러분은 어떻게 풀이하는가?
물론, 1단에서 하나씩 세어보고, 2단에서 하나씩 세어보고,,, 이럴 수도 있지만, 곱의 성질을 이해하고 있다면 8 / n단의 몫이 8보다 작거나 같은 수의 값이 된다는 것을 알 수 있다.
무슨 말인가 싶겠지만, 한 번 보면 이렇다.
1단을 예로들어보자. 8 / 1 = 8 로, 8보다 작거나 같은 수의 개수는 8개가 된다.
2단은? 8 / 2 = 4 로, 8보다 작거나 같은 수의 개수는 4개가 된다.
3단은? 8 / 3 = 2 로, 8보다 작거나 같은 수의 개수는 2개가 된다.
4단은? 8 / 4 = 2 로, 8보다 작거나 같은 수의 개수는 2개가 된다.
쭉 나열해보면 다음과 같아진다.
[기준 값 : 8]
1단 : {1, 2, 3, 4, 5, 6, 7, 8, 9} -> 8/1 = 8
2단 : {2, 4, 6, 8, 10, 12, 14, 16, 18} -> 8/2 = 4
3단 : {3, 6, 9, 12, 15, 18, 21, 24, 27} -> 8/3 = 2
4단 : {4, 8, 12, 16, 20, 24, 28, 32, 36} -> 8/4 = 2
5단 : {5, 10, 15, 20, 25, 30, 35, 40, 45} -> 8/5 = 1
6단 : {6, 12, 18, 24, 30, 36, 42, 48, 54} -> 8/6 = 1
7단 : {7, 14 ,21 ,28, 35, 42, 49, 56, 63} -> 8/7 = 1
8단 : {8, 16, 24, 32, 40, 48, 56, 64, 72} -> 8/8 = 1
9단 : {9, 18, 27, 36, 45, 54, 63, 72, 81} -> 8/9 = 0
총 8의 개수 = 20개
너무나 당연하겠지만, 예로들어 3단이라는 의미는 3를 단계적으로 누적 합을 한다는 의미다.
예로들어 사탕 8개를 3개씩 묶으면 2봉지가 묶여지고, 나머지 묶이지 않는 사탕 개수가 2개가 된다.
그러면 3개씩 묶인 개수는 결국 8개 안에서 최대한 만들 수 있는 묶음이 2개밖에 없다는 의미다.
왜 위 구구단을 설명할까? 앞서 2차원 행렬 A를 자세히 보았는가?
바로 각 행 혹은 열이 위와 같이 일종의 구구단이 되기 때문이다.
자, 앞서 우리는 무엇을 찾아야 한다고 했는가? 바로 𝑥 보다 작은 원소들의 개수를 찾는 것이 관건이었다.
그러면 위 구구단 설명에서 말했듯, 임의의 𝑥 에 대해 𝑥 보다 작은 원소의 개수를 찾을 수 있겠다.
예로들어 3보다 작은 원소의 개수를 찾는다고 해보자. 그러면 하나하나 탐색 할 필요 없이 그냥 각 단(i)로 나눠버리면 개수가 된다고 했다.
[𝑥=3]
1단 : 3 / 1 = 3
2단 : 3 / 2 = 1
3단 : 3 / 3 = 1
4단 : 3 / 4 = 0
총 5개다. 즉, 𝑥=3 에 대하여 𝑥보다 작거나 같은 수의 개수는 5개임을 알 수 있다.
그리고 5개라는 의미는 K=5 라는 의미도 된다.
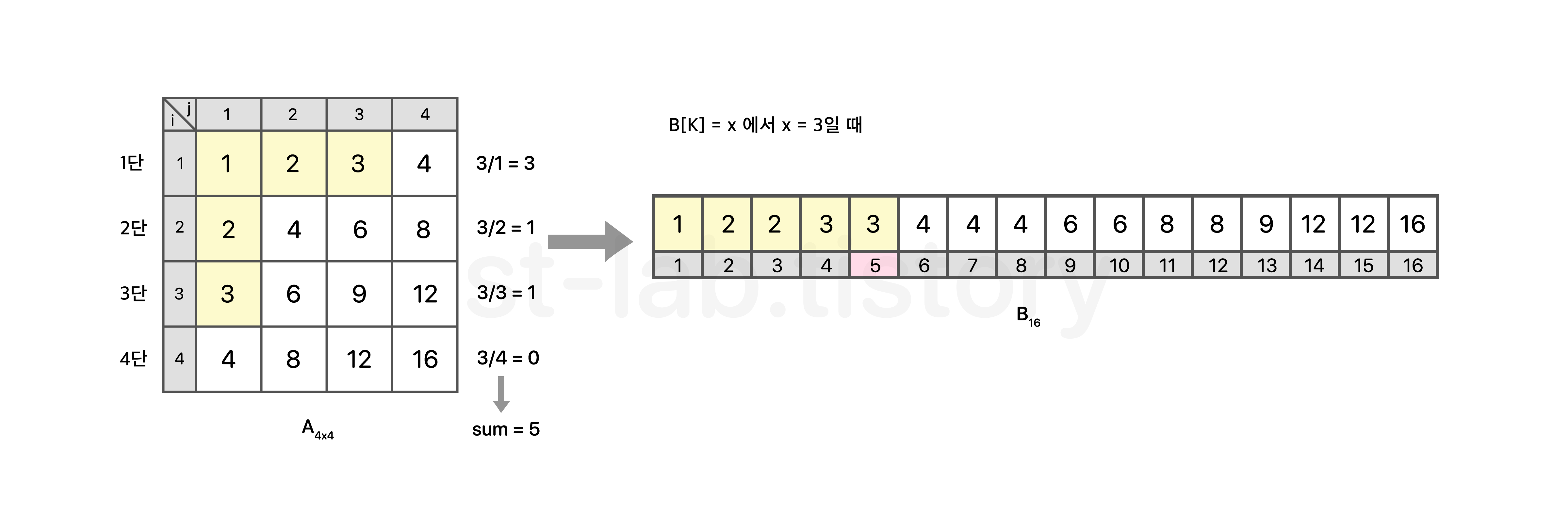
결국에는 행렬을 우리가 굳이 생성할 필요가 없게 된다.
1 ~ N까지 임의의 𝑥 로 나눠가면서 해당 합이 K와 같은지를 판별하면 되기 때문이다.
자, 그럼 이쯤에서 정리를 한 번 해보자.
B[K] = 𝑥 에서우리가 조정해가면서 탐색해야 하는 것은 𝑥 이다. 즉, 𝑥 를 통해 𝑥 보다 작은 원소의 개수(=K)를 찾고, 해당 값이 문제에서 주어지는 K값과 일치하는지를 이분탐색으로 구현을 하면 된다.
대충 아래와 같은 과정을 거치면 된다.
// 이분 탐색
// B[K] = x에 대해 x 는 left <= x < right 안의 수다.
while(left < right) {
mid = (left + right) / 2; // 임의의 x를 left 와 right의 중간 값으로 잡는다.
for(int i = 1; i <= N; i++) {
count += mid / i; // 각 단별 mid 보다 작거나 같은 수의 개수 합을 구한다.
}
// 임의의 x(mid)보다 작거나 같은 수의 개수(count)와 K의 값을 비교
if(count < K) {
// 하한 경계선(수의 범위 중 left)을 높인다.
}
else {
// 상한 경계선(수의 범위 중 right)을 낮춘다.
}
}
이 때 주의 할 점이 두 가지가 있다.
먼저, x보다 작은 원소의 개수를 찾을 때다. 우리가 x에 대해 이분탐색을 하지만, x는 어디까지나 임의의 수이기 때문에 다음과 같은 문제가 생길 수 있다.
먼저, 𝑥의 범위부터 생각해보자. 𝑥의 초기 범위는 1 ~ N2 까지이다. 예로들어 N=4라면 x의 초기 범위는 1 ≤ 𝑥 ≤ 16 이라는 의미다.
더 범위를 줄일 수는 없을까?
줄일 수 있다. 위를 보면, B행렬에서 𝑥 ≤ K 라는 것을 확인 할 수 있다. 당연하겠지만, K가 가질 수 있는 인덱스는 N2 안에서 한정되어 있고, K의 최댓값은 N2 이랑 같기 때문에 반드시 𝑥 ≤ K 일 수 밖에 없다. (위 예시에서 N=4일 때, K의 최댓값은 4 * 4 인 16이 될 것이다. 이는 A[4][4] = 4 * 4로 결국 B[16] = 16 으로 𝑥 는 N2 값을 벗어나지 못한다.
정리하자면 𝑥 의 범위를 1 ≤ 𝑥 ≤ K 로 좁힐 수 있다.
여기서 주의해야 할 점은 이분 탐색 과정에서 발생한다.
만약 이분탐색 과정에서 임의의 𝑥에 대해 𝑥=13 이 되었다고 가정해보자.
1단에 대해 13 / 1 = 13 이 될 것이다.
하지만, 우리가 A행렬에서 볼 수 있듯, 한 행에 대해 각 4개의 원소를 갖고 있다. 즉, 𝑥 보다 작은 원소의 개수는 최대 N개를 넘지 못한다.
2단도 마찬가지다.
13 / 2 = 6 으로 한 행에 대한 열의 개수를 초과하게 된다.
3단의 경우는 13 / 3 = 4로 13보다 작은 원소가 4개로 정확히 맞아 떨어지고, 4단의 경우는 13 / 4 = 3 으로, (4, 8, 12) 총 3개로 N = 4 안에서 개수를 갖게 된다.
즉, 앞서 보여주었던 수도 코드에서 다음과 같은 부분을
for(int i = 1; i <= N; i++) {
count += mid / i; // 각 단별 mid 보다 작거나 같은 수의 개수 합을 구한다.
}
아래와 같이 바꿔주어야 한다.
for(int i = 1; i <= N; i++) {
count += min(mid / i, N); // N을 초과하지 않는 선에서의 개수
}
두 번째로, Upper-Bound를 써야하는가, 아니면 Lower-Bound를 써야하는가의 문제다.
일단, 정답부터 말씀드리자면 Lower-Bound를 써야한다.
Upper-Bound는 찾고자 하는 값을 '초과 하는 첫 번째 인덱스(혹은 값)'를 찾는 것이다.
만약 N=4고, K=8로 주어졌다고 해보자.
우리가 이분 탐색에서 분기하는 기준은 무엇인가? 임의의 𝑥 보다 작거나 같은 수의 개수와 K를 비교하여 𝑥 의 범위를 좁혀 나간다.
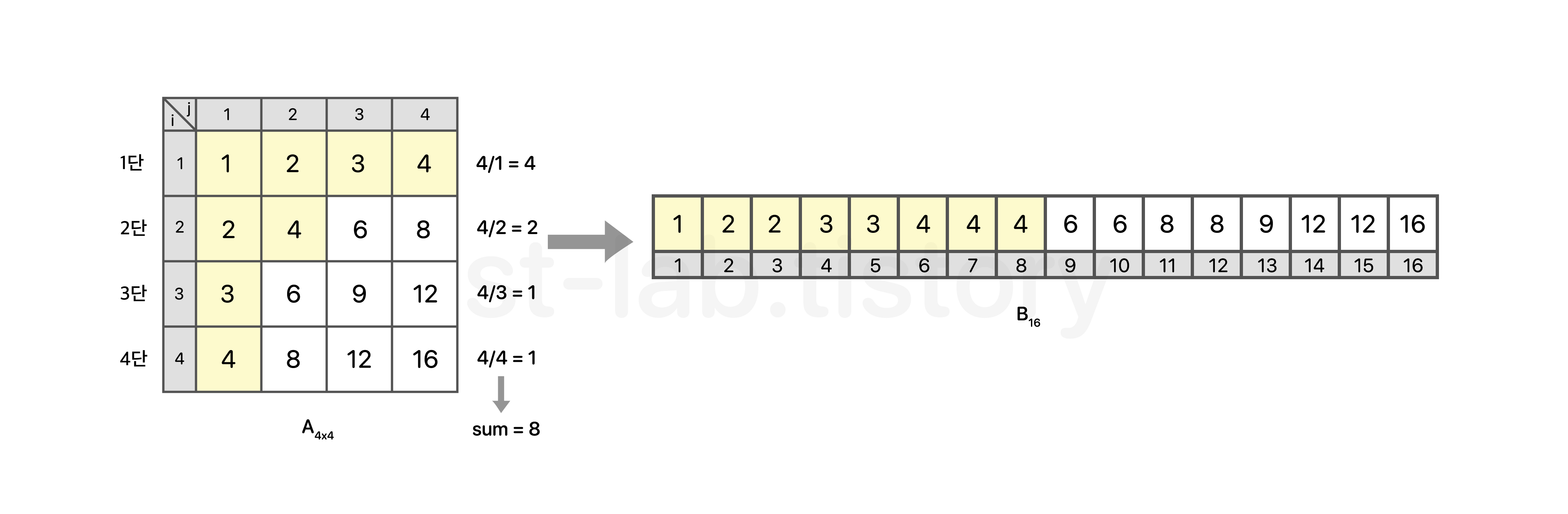
만약 위와같이 임의의 𝑥 가 4라면 sum = 8로 K와 같아지게 되면서 그 다음 값인 𝑥 = 5로 바뀌게 되고, 이분탐색이 종료되어 기존에 풀어왔듯이 𝑥 - 1을 출력하면 된다.
하지만, 𝑥 가 5라면 어떻게 되는가?
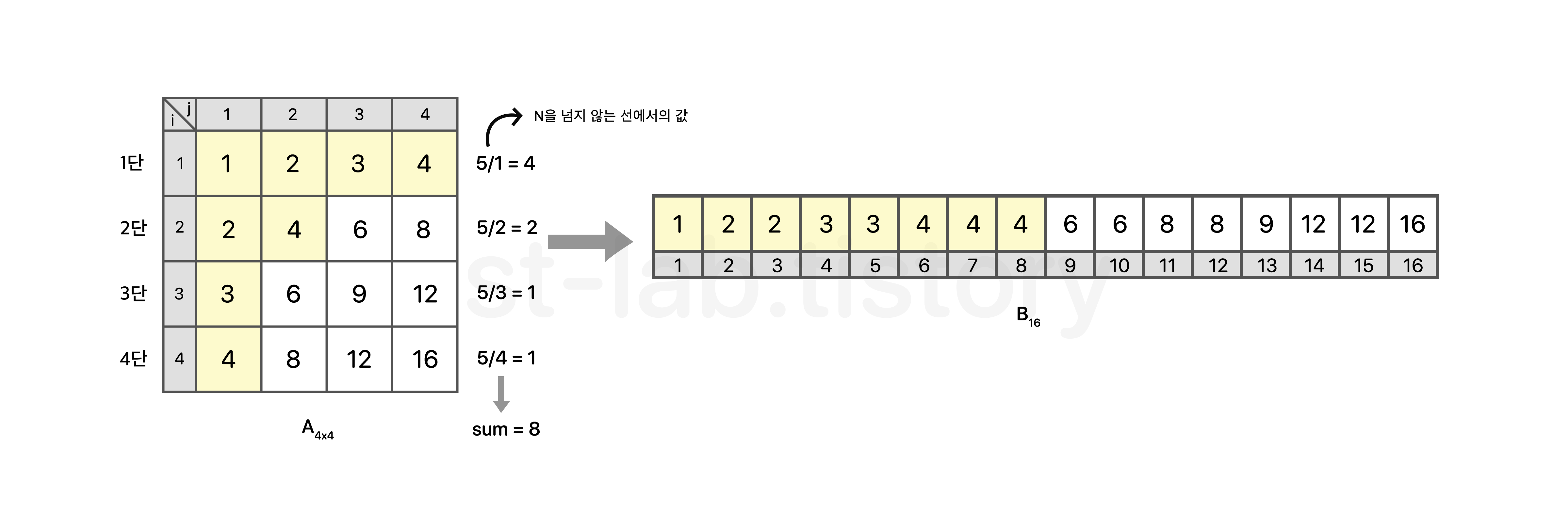
위와 같이 sum=8로 𝑥 가 4일때랑 K값이 같아지게 되고, 𝑥 는 결국 6이 되면서 이분 탐색을 끝내게 될 것이다. 이러한 원인으로 K값에 대해 𝑥 보다 작은 수가 K값이랑 같은 경우의 수가 여러개일 가능성이 발생하기 때문에 '찾고자 하는 값과 같거나 큰 수가 있는 첫 번째 인덱스'를 찾는 Lower-Bound를 써주어야 한다는 것이다.
그러면 이를 토대로 한 번 코드를 작성해보자.
- 2가지 방법을 사용하여 풀이한다.
이전 포스팅과 여타 다를 바 없이 아래와 같이 2가지 입출력 방법을 통해 성능을 비교해보려 한다.
1. Scanner
2. BufferedReader
- 풀이
- 방법 1 : [Scanner]
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int N = in.nextInt();
int K = in.nextInt();
// x는 lo <= x <= hi 의 범위를 갖는다.
long lo = 1;
long hi = K;
// lower-bound
while(lo < hi) {
long mid = (lo + hi) / 2; // 임의의 x(mid)를 중간 값으로 잡는다.
long count = 0;
/*
* 임의의 x에 대해 i번 째 행을 나눔으로써 x보다 작거나 같은 원소의 개수
* 누적 합을 구한다.
* 이 때 각 행의 원소의 개수가 N(열 개수)를 초과하지 않는 선에서 합해주어야 한다.
*/
for(int i = 1; i <= N; i++) {
count += Math.min(mid / i, N);
}
// count가 많다는 것은 임의의 x(mid)보다 작은 수가 B[K]보다 많다는 뜻
if(K <= count) {
hi = mid;
}
else {
lo = mid + 1;
}
}
System.out.println(lo);
}
}
가장 기본적인 방법이라 할 수 있겠다.
참고로 N의 길이가 최대 100,000 로 N*N 즉, B[K] 에서 K가 가질 수 있는 최댓값은 10,000,000,000(100억) 이다.
물론, 주어지는 K는 1,000,000,000 (10억)이므로, int 자료형 범위를 벗어나진 않지만, 그 안에서 누적합인 count 변수의 경우 int 자료형을 벗어 날 수 있으니 count는 long 타입으로 선언해주는 것이 안전하다.
- 방법 2 : [BufferedReader]
입력 방법을 Scanner 대신 BufferedReader 을 사용하여 풀이하는 방법이다.
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.IOException;
public class Main {
public static void main(String[] args) throws IOException {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int N = Integer.parseInt(br.readLine());
int K = Integer.parseInt(br.readLine());
// x는 lo <= x <= hi 의 범위를 갖는다.
long lo = 1;
long hi = K;
// lower-bound
while(lo < hi) {
long mid = (lo + hi) / 2; // 임의의 x(mid)를 중간 값으로 잡는다.
long count = 0;
/*
* 임의의 x에 대해 i번 째 행을 나눔으로써 x보다 작거나 같은 원소의 개수
* 누적 합을 구한다.
* 이 때 각 행의 원소의 개수가 N(열 개수)를 초과하지 않는 선에서 합해주어야 한다.
*/
for(int i = 1; i <= N; i++) {
count += Math.min(mid / i, N);
}
// count가 많다는 것은 임의의 x(mid)보다 작은 수가 B[K]보다 많다는 뜻
if(K <= count) {
hi = mid;
}
else {
lo = mid + 1;
}
}
System.out.println(lo);
}
}
- 성능

채점 번호 : 36720950 - 방법 2 : BufferedReader
채점 번호 : 36720944 - 방법 1 : Scanner
입력의 경우는 확실히 Scanner 보다는 BufferedReader 가 빠른 걸 볼 수 있다.
- 정리
이 번 문제는 아마 이해하는데 조금 어려움이 있을 것 같다. 위와 같은 과정을 파악하는게 결코 쉬운 일은 아니기 때문에 차근차근 하나씩 살펴보면 좋을 것 같다.
결국 무엇을 범위로 잡아야 하는지, 무엇을 기준으로 분기를 해야하는지에 대한 감각이 있어야 이분 탐색 문제를 좀 더 쉽게 풀 수 있다고 생각한다.
카테고리에서는 별로 이분탐색 문제가 없지만, 알고리즘 분류별로 들어가서 여러 이분탐색 문제들을 접해보면서 풀어보시는 것도 매우 좋은 방법이라고 본다.
만약 어렵거나 이해가 되지 않은 부분이 있다면 언제든 댓글 남겨주시면 최대한 빠르게 답변드리겠다.